AI agent observability shows what happened — but can't prevent what shouldn't. Learn why agents need runtime governance on top of tracing and evaluation.
1. The AI Agent Observability Promise
The AI agent observability market has matured fast. Two platforms lead and both deliver real value.
LangSmith provides framework-agnostic structured traces across LangChain, LangGraph, OpenAI, Anthropic, LlamaIndex, and custom stacks. Dashboards for tokens, latency (P50/P99), errors, cost; alerts via webhook or PagerDuty. Their 2025 Insights Agent surfaces common failure patterns. [Source: LangChain]
Arize Phoenix is open-source observability on OpenTelemetry: distributed tracing, LLM-as-judge evals, drift detection, retrieval quality across 50+ LLMs. Session-level eval of full conversations. MCP tracing added recently; Arize AX (enterprise) runs output-correction guardrails. [Source: Arize; Phoenix GitHub]
Genuinely useful. They're joined by Langfuse (MIT-licensed open-source), Pydantic Logfire, and HoneyHive in adjacent positions, with similar tracing and evaluation capabilities and the same architectural limit described below. LangSmith's tracing nails what an agent did; Arize's evals catch quality drift. If you're running agents with no observability, start there. The question is whether observability is where you stop.
2. Why It Works for Traditional Software
Observability (logs, metrics, traces) has been production software's reliability backbone for decades. In traditional systems, it's often sufficient.
Traditional software is deterministic: same input, same output. When it breaks, a stack trace points to a line; an error log names the exception; a metric spike correlates to a deployment. Failure modes are known and enumerable: null pointers, timeouts, deadlocks, memory leaks. You write runbooks.
Critically, traditional software keeps a human in the loop at every decision boundary. A web app processes requests; it doesn't decide what to do next. A CI/CD pipeline runs tests; it waits for a human to approve deploy. A database executes queries; it doesn't choose which ones.
In this world, observability works because:
- Failures are reproducible (same input, same bug)
- Root causes map to specific code paths
- Blast radius is bounded by request scope
- A human reviews the dashboard before the next decision
Observability tells you what happened. A human decides what to do. The loop closes.
3. Why Agents Are Different
AI agents break every assumption that makes traditional observability sufficient.
Non-deterministic execution. Same prompt, different outputs. Same agent, different tool choices, different orderings. Failures can't be reliably reproduced by replaying input. LangChain's 2025 State of Agent Engineering report: 89% of organizations run observability for their agents, yet quality remains the top production barrier (32% of respondents). Seeing what the agent did ≠ understanding why it did it. [Source: LangChain — State of Agent Engineering]
Autonomous decision-making. An agent decides what to do next. It picks tools, forms plans, evaluates intermediate results, adapts, all without human approval. Each decision is a branching point where a small error cascades. A misinterpretation at step one becomes wrong retrieval at step two becomes hallucinated policy at step three. By step ten the agent is operating in a reality unrelated to user intent.
Compounding errors. Traditional errors are isolated: an API call fails, the caller handles it. Agent errors propagate silently. An agent that retrieves wrong context doesn't know it's wrong, and every subsequent action is contaminated.
Cost as a runtime variable. A traditional API call has predictable cost. An agent's cost is unbounded, depending on steps, tokens, retries, and duration. A normal run might cost $3; the same agent hitting an edge case can cost $47,000, and every trace on the dashboard stays green. The agent isn't failing. It's doing exactly what it was designed to do: try to complete the task. It just never stops trying.
| Property | Traditional Software | AI Agent |
|---|---|---|
| Determinism | Same input, same output | Same input, different outputs |
| Decision-making | Follows explicit code paths | Chooses its own path at runtime |
| Error propagation | Isolated per request | Compounds across steps |
| Cost predictability | Fixed per operation | Variable, potentially unbounded |
| Failure detection | Errors throw exceptions | Agent may report "success" while failing |
| Human in the loop | At every decision boundary | Nowhere by default |
This is not a minor difference. It is a category difference. And it means observability tools designed for the left column have a structural limitation when applied to the right column.
4. What Does AI Agent Observability Actually Miss?
The observability gap, the space between knowing what happened and preventing it, shows up three specific ways.
Gap 1: Shows WHAT, Not WHY
Observability captures execution traces precisely. You see every LLM call, every tool invocation, every intermediate output. What you don't see is the agent's reasoning: why it chose tool A over B, how it interpreted ambiguous instructions, why it retried instead of escalating.
A LangSmith trace shows the sequence of calls. It doesn't show the decision logic that selected that sequence. The trace is a recording of actions; the reasoning is gone the moment the LLM generates its next token. Two identical trace patterns can have entirely different root causes (one loop from contradictory tool outputs, another from misinterpreted user goals). Same trace, different fixes.
Gap 2: Logs but Doesn't PREVENT
The most consequential gap. Observability tools sit alongside the execution pipeline, receiving events and storing them. They don't sit inside the pipeline with authority to stop it.
Three real-world failures where observability was present but damage still occurred:
The $47K Loop. A multi-agent system entered a retry spiral for 11 days, accumulating $47,000 in API costs. Monitoring was on. A monthly $5,000 account-level budget alarm (designed for normal operations) didn't fire per-execution. Status logs read "Schema drift resolution in progress" throughout. Every trace clean, every API call succeeded. Observability recorded 11 days of runaway spend perfectly. It didn't stop it. [Source: Tech Startups]
The Air Canada Chatbot. Air Canada's chatbot told a customer he could retroactively apply for bereavement fares, a policy that didn't exist. Conversation logs captured the wrong answer. Nothing in the observability pipeline flagged that it contradicted the company's actual policy. Customer booked, got denied, won a tribunal ruling. [Source: ABA — Moffatt v. Air Canada]
260 McNuggets. McDonald's AI drive-thru added 260 Chicken McNuggets to a single order. Every layer reported success: speech-to-text, NLU, order management, all working. Observability showed a perfectly functioning pipeline. The missing piece, business-logic validation asking whether 260 nuggets is reasonable, lives in a layer observability doesn't address. [Source: CNBC]
In each case: data to diagnose the failure was in the logs; infrastructure to prevent it was not.
Gap 3: Observes but Doesn't LEARN
Observability is stateless. Each trace is an independent record; the system doesn't learn from past failures to prevent future ones. If an agent enters a loop on Monday and you fix the specific trigger, a structurally identical loop with a different trigger will succeed on Tuesday.
A Galileo analysis of Arize put it directly: "No lifecycle management between offline evaluations and runtime protection. The systems remain disconnected. If you need runtime blocking, you're building it yourself or paying for multiple platforms." [Source: Galileo vs Arize] This describes the whole observability category, not Arize specifically. These tools were built to answer "what happened?" not "should this be allowed to happen?"

5. Why Is AI Agent Observability Insufficient on Its Own?
Observability tells you what happened; governance tells the agent what it's allowed to do. Closing the gap requires four capabilities observability tools don't provide:
- Reasoning Visibility. Traces show execution; reasoning visibility shows intent: which options the agent considered, why it picked one. Answers "why did it think this was right?" not just "what did it do?"
- Policy Enforcement. Rules enforced at runtime with hard authority. Observability-only: agent issues a $2,000 refund, trace records it, you find out at morning review. Enforcement: the refund is blocked before money moves. Smoke detector vs. sprinkler.
- Execution Bounds. Circuit breakers, not alerts. An alert at $100 says the agent already spent $100; a bound at $100 stops the agent from spending $101. In the $47K Loop, the difference between alert and bound was $46,900.
- Adaptive Learning. Static rules catch known failures; adaptive learning catches new ones (emerging loops, behavioral drift, a tool returning degraded results), adjusting constraints without manual tuning.

6. From Observability to Governance
Governance doesn't replace observability. It's observability plus two additional layers: control and intelligence.
| Layer | What It Does | Example |
|---|---|---|
| Observability | Records what happened | "Agent made 47 API calls in 3 minutes" |
| Control | Enforces what is allowed | "Agent is halted after 100 steps per execution" |
| Intelligence | Learns what should change | "Step count is 4× the 30-day average, flag for review" |
Observability alone: you see 47 API calls, but after the fact. If they cost $500 each, you see $23,500 spent — after the fact.
Control adds bounds: 100 steps, $10 per execution, 3 iterations per sub-task. When a bound hits, execution stops. Damage capped.
Intelligence compares this run against historical baselines. Anomalies (unusual step counts, unexpected tool usage, cost trajectories outside norms) flag or halt executions.
The three layers compound. Observability without control produces excellent post-mortems. Control without intelligence produces brittle rules needing constant tuning. Intelligence without observability has nothing to learn from. Together they form a governance layer that's adaptive, enforceable, and transparent.
Governance = Observability + Control + Intelligence
This is the architecture of the Agent Kernel: the runtime governance layer between agent and environment that provides visibility, enforcement, and learning as one capability. It's the minimum required to run autonomous agents in production where they spend money, face customers, or take real-world actions.
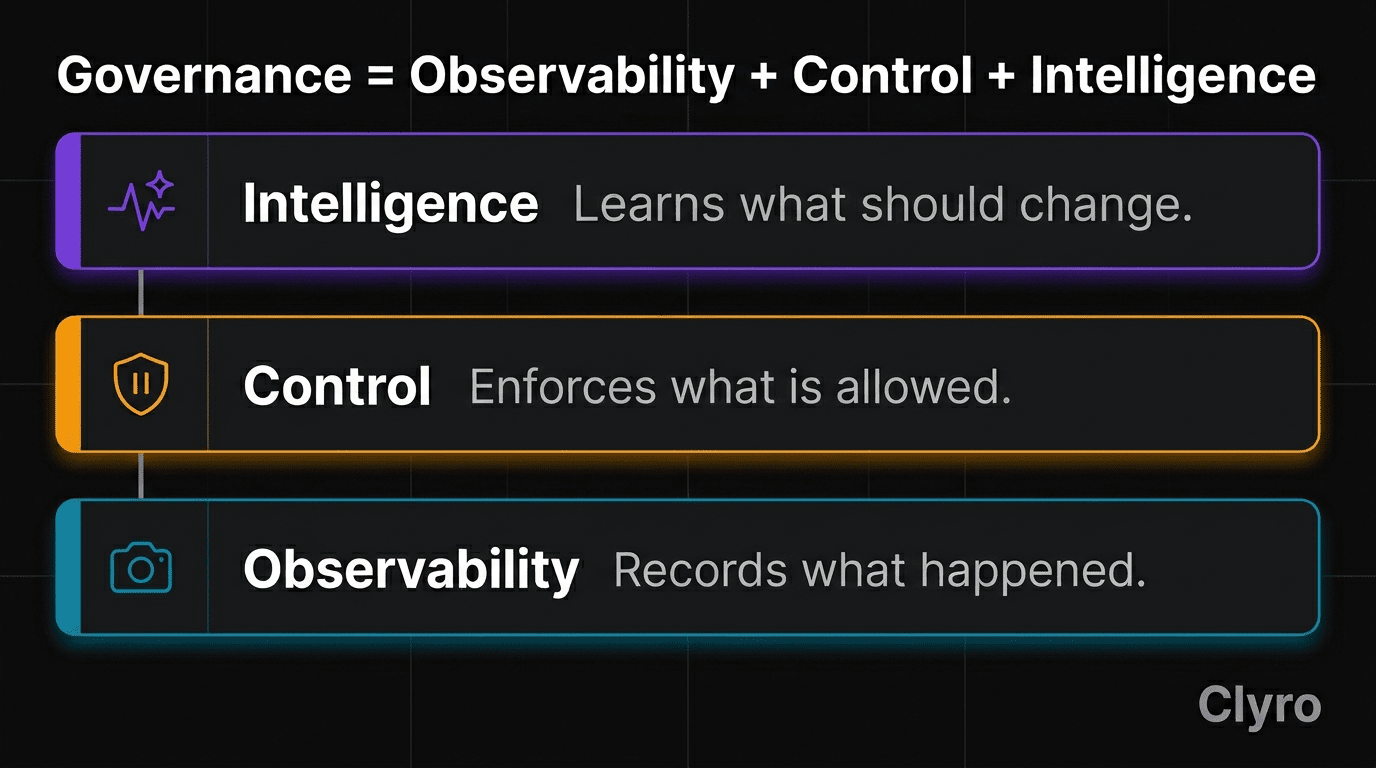
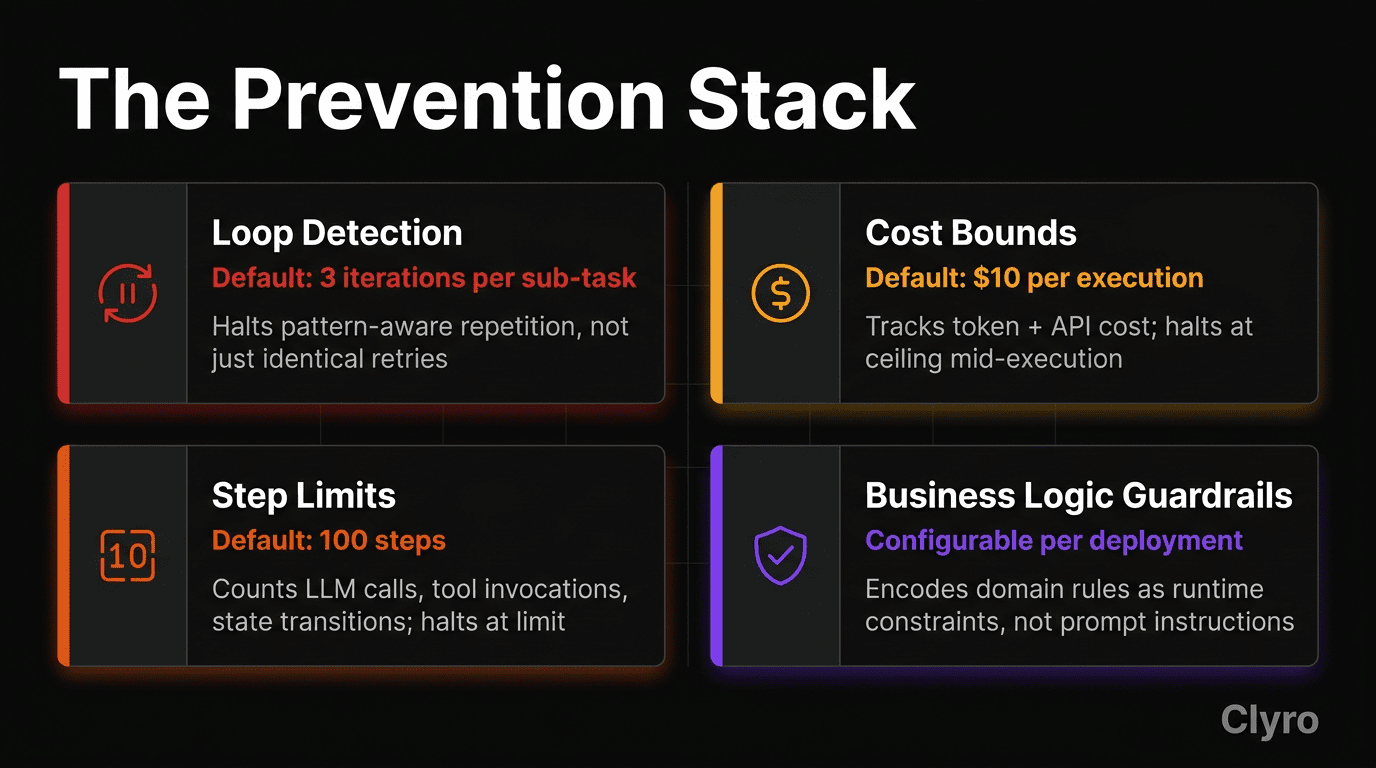
7. The Prevention Stack
Governance becomes concrete through four components. Each targets a specific failure mode. Each has a sensible default. Together, they form the Prevention Stack: a runtime layer that sits between the agent and its environment, enforcing boundaries while the agent operates.
| Component | What it does | Default | What observability misses |
|---|---|---|---|
| Loop Detection | Halts when action-sequence repetition (identical calls, circular delegation, retries on same failed op) exceeds threshold | 3 iterations per sub-task | Pattern-aware repetition even when specific actions vary (the $47K agent generated different migration scripts each time, so duplicate detection wouldn't catch it) |
| Cost Bounds | Tracks cumulative tokens + API cost during execution; halts at ceiling | $10 per execution (most runs <$1; the $47K incident would've been a $10 incident) | Mid-execution cost accumulation (dashboards show aggregate spend, not single-run trajectory) |
| Step Limits | Counts LLM calls, tool invocations, state transitions; halts at limit | 100 steps (well-designed tasks complete in 5–20) | A 500-step trace looks the same as a 5-step trace: both valid execution records |
| Business Logic Guardrails | Executable constraints enforced before specific actions ("max refund without approval: $200", "max quantity per menu item: 20") | Configurable per deployment | The 260 McNuggets order was technically flawless; observability can't encode your business logic |
Four governance features, not observability features. They don't record what happened. They constrain what can happen.
8. Resolution: Keep Observability. Add Governance.
Observability is necessary: the foundation. Without traces you can't diagnose failures; without metrics you can't measure reliability; without evals you can't detect quality drift.
It's not sufficient. Traces don't prevent loops, dashboards don't enforce cost ceilings, evals don't stop an agent from telling a customer something false.
The path isn't replacing observability. It's adding a governance layer on top.
Keep LangSmith for traces. Keep Arize for evals. Add runtime governance (loop detection, cost bounds, step limits, business logic guardrails) to close the gap between seeing failures and preventing them. OpenTelemetry (OTLP/HTTP and gRPC) is the integration point. A governance layer that emits and consumes OTLP keeps your existing Datadog, Grafana, and LangSmith stack running, and adds what they can't: runtime prevention. Same data pipeline, new enforcement.
The industry is moving here. LangChain's State of Agent Engineering shows 89% of teams have observability, yet quality remains the top production barrier. [Source: LangChain] Gartner predicts 40%+ of agentic AI projects canceled by end of 2027: escalating costs, unclear ROI, inadequate risk controls. [Source: Gartner, June 2025; Composio] The gap isn't visibility. It's control.
Observability answers: "What happened?"
Governance answers: "What is allowed to happen?"
You need both.
Start here
- Add a per-execution cost ceiling to every agent deployment (default: $10)
- Implement step limits on every agent loop (default: 100 steps)
- Add loop detection for retry patterns (default: halt after 3 iterations)
- Encode your business rules as runtime constraints, not prompt instructions
Get Started
Install the SDK and add runtime governance to your agents in under a minute.
pip install clyro
Free tier: 10 agents, 100K traces/month, no credit card required.
Works with LangGraph, CrewAI, Claude Agent SDK, Anthropic SDK, and any Python callable.
Sign Up Free → | GitHub → | Docs →
FAQ
Aren't tools like LangSmith or Arize Phoenix enough for production AI agents?
Necessary but not sufficient. Both platforms record what happened; they don't prevent it. In the $47K Loop, LangSmith-style traces stayed clean for 11 days while the agent burned cash. The Air Canada chatbot's wrong answer was traceable but nothing blocked it before the customer relied on it. You need observability and a governance layer that intervenes during execution, not after.
What's the actual difference between observability and governance?
Observability tells you what happened. Governance tells the agent what it's allowed to do. Observability sits alongside execution, storing events for analysis. Governance sits inside execution with authority to halt. The formula: Governance = Observability + Control + Intelligence. Omit Control or Intelligence and you get the gap this article describes.
Why can't observability tools prevent agent failures if they see everything?
Because they record, not intervene: a trace is a recording, not a gate. Even "runtime guardrails" like Arize AX typically do output correction, not execution blocking. And many failures look identical to successes in logs: 260 McNuggets had speech-to-text working, NLU working, order management working, with no layer checking quantity. Observability can't catch business-logic violations because it doesn't encode your business logic.
Do I need to replace my existing observability stack to add governance?
No. Keep LangSmith, Arize, Datadog, Grafana, all unchanged. Add a governance layer that speaks OpenTelemetry OTLP (HTTP or gRPC). It emits/consumes OTLP data, so your existing infrastructure keeps working; it just gets additional enforcement events. Same pipeline, new prevention. The architecture is designed to compose.
What's the minimum runtime governance I should add today?
Four capabilities with sensible defaults: (1) Cost bounds — $10 per execution; most runs cost <$1, so the $47K incident becomes a $10 incident. (2) Step limits — 100 steps; well-designed tasks complete in 5–20. (3) Loop detection — halt after 3 iterations per sub-task, pattern-aware not duplicate-aware. (4) Business logic guardrails — encode domain rules as runtime constraints, not prompt instructions. Not speculative tech; just not deployed yet.
How does the Prevention Stack fit alongside OpenTelemetry, LangSmith, and Arize?
The Prevention Stack sits between the agent and its tools/APIs; observability platforms sit parallel, receiving events. OTLP is the shared protocol. The Prevention Stack emits OTLP spans for every enforcement event (loop halted, cost ceiling reached, rule blocked), and those flow into LangSmith/Arize alongside normal traces. You see "agent made 47 API calls" and "48th call halted by step-limit guardrail" in one view.
Is runtime governance practical at agent scale, or does it add too much overhead?
Practical. Checks add a few ms per tool call, far less than LLM inference (hundreds of ms to seconds). Cost bounds, step limits, loop detection are in-memory counters; business-logic guardrails are pre-call rule evaluations. Context validation against an authoritative source adds 10–50ms, still negligible. The real question isn't performance — it's discipline: versioning policies, calibrating defaults as agent behavior evolves, reviewing halted runs.
Related Resources
- The 5 Agent Failure Modes — The taxonomy of how agents fail in production
- The $47K Loop: A Complete Forensic Analysis — Day-by-day reconstruction of a runaway agent incident
- 260 McNuggets: When AI Orders for You — When observability shows green but the business outcome is absurd
- The Prevention Stack: Beyond Observability — Deep dive into the four components of runtime governance
For the full architecture of the Prevention Stack, see The Prevention Stack: Beyond Observability.
Sources
[1] LangChain — LangSmith Observability — LangSmith tracing and monitoring capabilities. https://www.langchain.com/langsmith/observability
[2] Arize — Agent Observability and Tracing — Arize Phoenix agent observability features. https://arize.com/ai-agents/agent-observability/
[3] Arize Phoenix GitHub Repository — Open-source AI observability built on OpenTelemetry. https://github.com/Arize-ai/phoenix
[4] LangChain — State of Agent Engineering — Survey showing 89% observability adoption yet quality remains top barrier. https://www.langchain.com/state-of-agent-engineering
[5] Tech Startups — $47,000 AI Agent Failure, November 2025 — Multi-agent runaway cost incident. https://techstartups.com/2025/11/14/ai-agents-horror-stories-how-a-47000-failure-exposed-the-hype-and-hidden-risks-of-multi-agent-systems/
[6] ABA — Companies Remain Liable for AI Chatbot Information — Air Canada chatbot tribunal ruling analysis. https://www.americanbar.org/groups/business_law/resources/business-law-today/2024-february/bc-tribunal-confirms-companies-remain-liable-information-provided-ai-chatbot/
[7] CNBC — McDonald's Ends AI Drive-Thru Test, June 2024 — McDonald's 260 McNuggets AI ordering failure. https://www.cnbc.com/2024/06/17/mcdonalds-to-end-ibm-ai-drive-thru-test.html
[8] Galileo — Galileo vs Arize Comparison — Analysis of observability platform lifecycle management gaps. https://galileo.ai/blog/galileo-vs-arize
[9] Gartner — Over 40% of Agentic AI Projects Canceled by End of 2027 (June 2025 press release) — Primary source for the cancellation prediction. https://www.gartner.com/en/newsroom/press-releases/2025-06-25-gartner-predicts-over-40-percent-of-agentic-ai-projects-will-be-canceled-by-end-of-2027
[10] Composio — Why AI Agent Pilots Fail — Industry analysis citing Gartner forecast. https://composio.dev/blog/why-ai-agent-pilots-fail-2026-integration-roadmap