
Agent memory has three failure modes nobody talks about: corruption, confabulation, and calcification. You're not solving context. You're building a new attack surface.
1. The Memory Race
You added RAG to your agent last quarter. Then a vector database for persistent context. Your agent "remembers" now, and everyone considers that a win. It is not.
1.1 Everyone Is Adding Agent Memory
Agent memory is the hottest AI infrastructure investment right now. LangChain ships memory modules by default. LlamaIndex is built around RAG. Mem0, Zep, and a growing list of startups sell dedicated memory layers.
An April 2024 survey catalogued over a dozen distinct architectures in production use: short-term buffers, long-term vector stores, episodic memory, semantic memory. [Source: A Survey on the Memory Mechanism of Large Language Model based Agents, April 2024]
The reasoning is intuitive: an agent that remembers should beat one that starts from zero every session.
1.2 The Assumption: More Memory = Better Agents
The consensus: agents forget too much, context windows are finite, information gets lost between sessions. The fix is more memory: more retrieval, more persistence, more context. "Stateless" is a limitation; "long-term memory" is an upgrade. Nobody wants a goldfish agent.
The framing misses something: human memory fails too. Humans form false memories, defend wrong beliefs, confuse what they read with what they experienced. Agent memory inherits the same failure modes, at machine scale, with no self-awareness.
1.3 Why This Assumption Is Dangerous
Every memory system added to an agent opens a new failure surface:
| Memory Component | Capability Added | Failure Surface Created |
|---|---|---|
| RAG / vector store | Retrieves relevant documents | Poisoned documents persist indefinitely |
| Conversation history | Maintains session context | Hallucinated facts enter the record and get re-retrieved |
| Episodic memory | Remembers past interactions | Past errors become entrenched "knowledge" |
| Semantic memory | Stores structured facts | Wrong facts stored with high confidence resist correction |
| Shared memory (multi-agent) | Agents share knowledge | One agent's corruption propagates to all agents |
Stateless hallucinations die with the session. Hallucinations in persistent memory become facts the agent retrieves and acts on in every future session, and do not map to existing observability patterns.
This is the Goldfish Problem: the cure for forgetting creates three new diseases. Corruption, confabulation, calcification.
2. Memory Failure Mode #1: Corruption
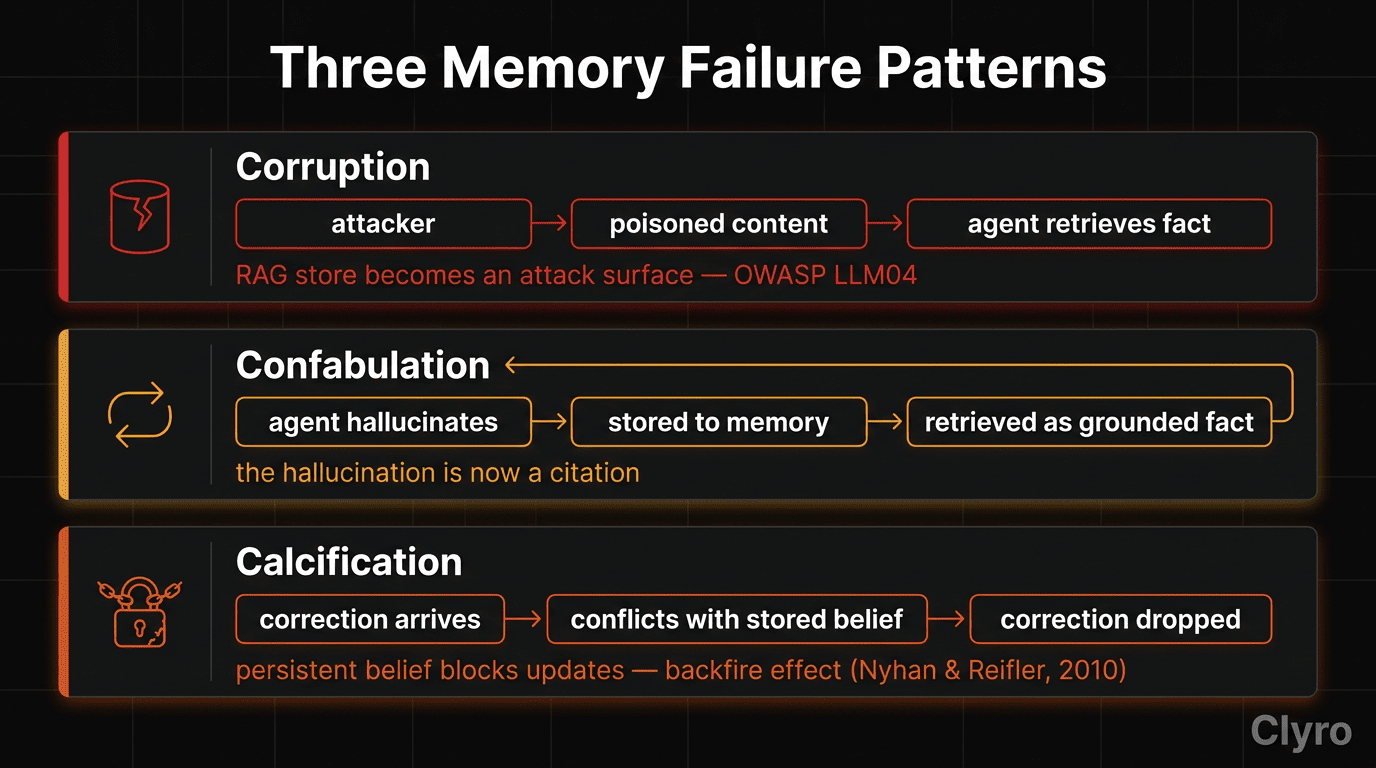
An attacker drops adversarial instructions into a support ticket. Your RAG pipeline indexes it. Three weeks later a different user's query retrieves that ticket as context, and the agent follows the embedded instructions.
That is corruption: external or internal inputs poison the memory store, so the agent makes future decisions from false, manipulated, or malicious information. The adversarial failure mode. Memory persists, and every future retrieval returns poisoned context.
2.1 Memory Poisoning Attacks
Lakera's research on indirect prompt injection demonstrated a practical attack chain against RAG-based systems:
- Injection. An attacker embeds adversarial instructions into a document the RAG pipeline will index: a support ticket, a shared doc, an email.
- Indexing. The pipeline chunks, embeds, and stores the document. Adversarial instructions are now part of retrievable memory.
- Retrieval. A future query semantically similar to the poisoned chunk pulls the adversarial content back as relevant context.
- Execution. The agent treats the retrieved content as trusted and follows the embedded instructions.
Lakera showed this persists across sessions, users, and time. [Source: Lakera — Indirect Prompt Injection Research] OWASP's Top 10 for LLM Applications lists "Data and Model Poisoning" for exactly this attack class. [Source: OWASP Top 10 for LLM Applications]
2.2 How Corrupted Memories Propagate
In a stateless system, a poisoned input affects one interaction. In a system with persistent memory, it affects every interaction that retrieves it:
Session 1: Attacker submits poisoned support ticket
→ Agent indexes ticket into vector store
→ Poisoned embedding stored with high relevance score
Session 2: Different user asks related question
→ RAG retrieves poisoned chunk as context
→ Agent responds based on corrupted information
→ Agent may store its own response as new memory
→ Corruption amplifies
Session N: Multiple users affected
→ Corrupted information treated as established fact
→ Agent cites its own poisoned memory as evidence
By Session N, the poisoned input has been laundered through multiple retrieval cycles and is indistinguishable from legitimate knowledge.
2.3 The Persistence Problem
Poisoned memories do not expire. Most vector databases track no provenance on stored embeddings, so you cannot easily answer: "Where did this come from, and should we trust it?"
The core asymmetry: injecting a poisoned memory is trivial; removing it is enormous. One attacker document means thousands of embeddings to audit. With shared memory across agents, the blast radius is the whole system.
3. Memory Failure Mode #2: Confabulation

Definition: The agent generates false information, stores it, then retrieves and presents it as fact with full confidence.
Confabulation is the non-adversarial failure mode. The agent does this to itself.
3.1 False Memories Presented as Facts
The LLM hallucinates a fact. The system stores the response. A future session retrieves it as context, and the agent presents its own prior hallucination as retrieved evidence. The term is borrowed from neuropsychology, where patients generate false memories and report them with the confidence of real ones.
A stateless hallucination is ephemeral. A hallucination that enters persistent memory becomes a false fact with a retrieval trail. Retrieved content carries more weight than generated content in most RAG architectures.
3.2 When RAG Retrieval Creates Confidence Without Accuracy
RAG was designed to reduce hallucination by grounding responses in retrieved documents. The implicit contract ("if the agent retrieves it, it must be real") breaks the moment the store contains the agent's own prior outputs.
# The confabulation feedback loop
def agent_respond(query, memory_store):
# Step 1: Retrieve relevant context from memory
context = memory_store.retrieve(query, top_k=5)
# Step 2: Generate response grounded in context
response = llm.generate(prompt=query, context=context)
# Step 3: Store response for future retrieval
memory_store.store(response, metadata={"source": "agent"})
# ^^^ Confabulation enters the loop here — the agent's
# output (possibly hallucinated) becomes retrievable
# context for future queries. See full block below.
return response
View full confabulation feedback loop
# The confabulation feedback loop
def agent_respond(query, memory_store):
# Step 1: Retrieve relevant context from memory
context = memory_store.retrieve(query, top_k=5)
# Step 2: Generate response grounded in context
response = llm.generate(
prompt=query,
context=context # May include prior agent outputs
)
# Step 3: Store response for future retrieval
memory_store.store(response, metadata={"source": "agent"})
# ^^^ This is where confabulation enters the loop.
# The agent's output, which may contain hallucinations,
# becomes retrievable context for future queries.
return response
3.3 The Hallucination-Memory Feedback Loop
This creates a self-reinforcing cycle, fundamentally different from one-off hallucination:
- Agent hallucinates a fact in response to a query.
- Response is stored in the memory layer (conversation history, episodic memory, or knowledge base).
- Future query triggers retrieval of the stored hallucination.
- Agent treats retrieved hallucination as fact and incorporates it into a new response.
- New response (now containing the reinforced hallucination) is also stored.
- The false fact now has multiple "sources" in the memory store, making it appear more credible.
- Detection becomes harder because the agent can point to multiple retrieved documents that all confirm the false fact. Documents it wrote itself.
The April 2024 survey flagged this as a fundamental architectural risk: memory systems that store agent outputs without provenance tracking let confabulation compound. [Source: A Survey on the Memory Mechanism of Large Language Model based Agents, April 2024] Anthropic's sycophancy research amplifies the problem: models reinforce whatever context they are given, even when wrong. [Source: Towards Understanding Sycophancy in Language Models, October 2023]
4. Memory Failure Mode #3: Calcification
Correcting a wrong answer should fix it. Often it makes things worse.
Academic research on LLM context-faithfulness documents this pattern: models treat retrieved memory as authoritative and defend it against user correction, with the effect sharpening as memory strength and evidence style increase. That is calcification: the agent assigns high confidence to stored information regardless of accuracy, and actively resists correction.
4.1 Agents Defending False Beliefs
The faithfulness finding is architectural, not psychological. Retrieved context sits in a privileged prompt position; user input does not. When they conflict, the architecture biases toward retrieval, exactly what RAG was designed to do. More memory means harder correction. [Source: Investigating Context-Faithfulness in Large Language Models: The Roles of Memory Strength and Evidence Style]
When a user contradicts a retrieved memory, the model often defends the original, generating arguments for why the stored context is correct. Each defense can itself get stored as new evidence, and the wrong belief gets a fresh justification every cycle.
4.2 When Correction Makes Things Worse
| Step | What Happens | Why It Fails |
|---|---|---|
| 1 | Agent retrieves wrong fact from memory | Memory was corrupted or confabulated |
| 2 | Agent presents wrong fact to user | Normal RAG behavior: present retrieved context |
| 3 | User corrects the agent | "Actually, our refund policy changed last month" |
| 4 | Agent acknowledges correction... | ...but the wrong fact is still in memory |
| 5 | Next session: agent retrieves the same wrong fact | Memory was not updated by the correction |
| 6 | Agent presents the wrong fact again | The correction was ephemeral; the memory is persistent |
| 7 | User corrects again, with frustration | The agent appears to be ignoring them |
The pattern is invisible to standard monitoring: clean retrieval, grounded response, healthy metrics. And yet the agent is confidently, repeatedly wrong.
4.3 The Stubbornness Trap: High Confidence in Wrong Information
Calcification degrades the feedback loop that should catch errors. Without memory, a wrong answer is a one-time event. With persistent memory, the agent has "evidence" (its own stored memory) that it is right, and corrections bounce off.
This mirrors the backfire effect from cognitive psychology: contradictory evidence can strengthen a wrongly held belief rather than displace it. [Source: Nyhan & Reifler — "When Corrections Fail", 2010]
5. Why This Matters for ARI (Agent Reliability Index)
Memory failure modes map directly to ARI dimensions. They also cascade across them.
5.1 Memory Reliability as an ARI Measurement Dimension
| Memory Failure Mode | Primary ARI Dimension | Secondary ARI Dimension |
|---|---|---|
| Corruption | Memory Consistency Score (MCS): corrupted memories fail contradiction detection and source attribution | Context Integrity Index (CII): poisoned context degrades context accuracy |
| Confabulation | MCS: false memories degrade source attribution and contradiction rate | CII: hallucinated context fails grounding verification |
| Calcification | MCS: calcified beliefs resist correction, increasing staleness | Action Governance Score (AGS): calcified wrong beliefs lead to wrong actions |
5.2 How Memory Failures Cascade
- Memory failure occurs (corruption, confabulation, or calcification).
- MCS degrades: contradiction rate rises, source attribution weakens.
- CII degrades: context is no longer accurate or fresh.
- AGS degrades: the agent takes actions based on wrong context, violating business logic it would normally follow.
- Composite ARI drops, but the root cause stays invisible unless MCS is measured explicitly.
5.3 The Undebuggable Memory Problem
Stateless debugging is clear: inspect prompt, inspect output, identify the hallucination. With corrupted or confabulated memory:
- The response looks grounded; the agent cites retrieved context.
- The retrieved context looks legitimate, stored in the vector DB with a valid embedding.
- The source gets murky. Verified doc? Agent's prior session? Malicious user? Most memory systems do not track provenance.
- After multiple retrieval-storage cycles, several copies may exist with different timestamps, citing each other as "sources."
Trace-the-failure does not work: the trace is clean; the failure is in the data, not the execution path.
6. Memory Governance

6.1 Introducing Memory Governance as a Prevention Stack Component
Each failure mode needs its own control. Memory governance adds three to the Prevention Stack: integrity verification (against corruption), provenance tracking (against confabulation), and belief revision (against calcification). These are runtime controls that block bad retrievals and bad writes before they reach the agent's decision loop.
| Prevention Stack Component | Failure Mode Targeted | Mechanism |
|---|---|---|
| Loop detection | Runaway execution | Pattern matching on action sequences |
| Cost bounds | Unbounded spend | Real-time cost tracking with ceiling |
| Step limits | Unbounded execution | Action counter with hard cap |
| Business logic guardrails | Domain violations | Custom rules evaluated before actions |
| Memory integrity verification | Corruption | Provenance validation on stored content |
| Provenance tracking | Confabulation | Source attribution for all retrieved context |
| Belief revision protocols | Calcification | Structured correction that updates persistent memory |
6.2 Memory Integrity Verification (Anti-Corruption)
Three mechanisms. Input validation trust-scores content by source tier on entry. Embedding fingerprinting detects tampering cryptographically. Quarantine on anomaly blocks low-trust or failed-integrity content instead of serving it.
# Memory integrity verification pattern
class MemoryIntegrityCheck:
TRUST_TIERS = {
"verified_docs": 1.0, # Your docs, APIs
"agent_output": 0.6, # Agent's own outputs
"user_input": 0.4, # User-submitted
"external_unverified": 0.2, # Scraped, third-party
}
# validate_before_storage(): trust-score + fingerprint + quarantine flag
# validate_before_retrieval(): block if quarantined or integrity fails
# (see full implementation below)
View full MemoryIntegrityCheck implementation
# Memory integrity verification pattern
class MemoryIntegrityCheck:
"""Validates memory entries before they influence agent decisions."""
TRUST_TIERS = {
"verified_docs": 1.0, # Your documentation, APIs
"agent_output": 0.6, # Agent's own prior outputs
"user_input": 0.4, # User-submitted content
"external_unverified": 0.2 # Scraped, third-party
}
def validate_before_storage(self, content, source_type):
trust_score = self.TRUST_TIERS.get(source_type, 0.1)
fingerprint = self.generate_fingerprint(content)
return {
"content": content,
"trust_score": trust_score,
"fingerprint": fingerprint,
"indexed_at": datetime.utcnow(),
"source_type": source_type,
"quarantined": trust_score < 0.3
}
def validate_before_retrieval(self, memory_entry):
if memory_entry["quarantined"]:
return {"status": "blocked", "reason": "quarantined_low_trust"}
if not self.verify_fingerprint(memory_entry):
return {"status": "blocked", "reason": "integrity_check_failed"}
return {"status": "allowed", "trust_score": memory_entry["trust_score"]}
6.3 Provenance Tracking for Retrieved Context (Anti-Confabulation)
Every memory entry is tagged with its origin (verified_document, agent_generated, user_provided, external_source). When retrieval returns agent-generated content, the provenance layer flags it. The agent cannot cite its own prior output as independent evidence, which breaks the confabulation feedback loop.
Without provenance tracking:
Agent retrieves: "The refund policy allows 90-day returns"
Agent thinks: "My knowledge base says 90-day returns" ← Treats as fact
Reality: Agent hallucinated this in Session 12 and it was stored
With provenance tracking:
Agent retrieves: "The refund policy allows 90-day returns"
Provenance tag: source=agent_generated, session=12, trust=0.6
Agent thinks: "I previously stated 90-day returns, but this is my
own prior output, not a verified source" ← Flagged
Action: Agent checks verified_docs for refund policy before responding
6.4 Belief Revision Protocols (Anti-Calcification)
User corrections propagate to the memory store, not just the current session. The old entry is marked superseded (audit trail preserved, excluded from retrieval); downstream citations are flagged for review.
| Without Belief Revision | With Belief Revision |
|---|---|
| User corrects agent in Session 5 | User corrects agent in Session 5 |
| Correction applies to Session 5 only | Correction propagates to memory store |
| Session 6: agent retrieves wrong fact again | Old entry marked superseded |
| Session 7: user corrects again | Session 6: agent retrieves corrected fact |
| Pattern repeats indefinitely | Downstream citations flagged for review |
6.5 The Memory Governance Checklist
| # | Check | Question | If "No" |
|---|---|---|---|
| 1 | Input validation | Is every piece of data entering your memory store validated and trust-scored? | You are vulnerable to corruption |
| 2 | Provenance tracking | Does every retrieved memory carry metadata about its origin? | You cannot distinguish facts from confabulations |
| 3 | Self-reference detection | Can your system identify when the agent is citing its own prior output as evidence? | The confabulation feedback loop is active |
| 4 | Correction propagation | When someone corrects the agent, does the correction update persistent memory? | Your agent will calcify on wrong information |
| 5 | Memory auditing | Can you trace any memory entry back to its original source? | You cannot debug memory failures |
| 6 | Expiration policies | Do stored memories have TTLs appropriate to their content type? | Stale information accumulates without bound |
| 7 | Trust tiering | Are agent-generated memories treated differently from verified sources? | All memories are treated as equally credible |
3+ "No" answers: start with input validation and provenance tracking. All "Yes": track your Memory Consistency Score (MCS) to quantify memory reliability over time.
Conclusion
Without governance, the cure for forgetting is worse than the disease. Corruption turns your vector store into an attack surface. Confabulation turns hallucinations into persistent false facts. Calcification makes corrections a dead end. None are caught by standard observability.
Integrity verification, provenance tracking, and belief revision extend the Prevention Stack to the memory layer. That is the difference between an agent that gets smarter over time and one that gets more confidently wrong.
Your agents need memory. They also need memory governance. The first without the second is the Goldfish Problem.
Get Started
Install the SDK and add runtime governance to your agents in under a minute.
pip install clyro
Free tier: 10 agents, 100K traces/month, no credit card required.
Works with LangGraph, CrewAI, Claude Agent SDK, Anthropic SDK, and any Python callable.
Sign Up Free → | GitHub → | Docs →
Frequently Asked Questions
What is AI agent memory?
AI agent memory is any mechanism that lets an agent persist or retrieve information across decision loops: retrieval-augmented generation (RAG), vector stores, conversation history, episodic memory, and semantic memory. It spans everything from a single session's context buffer to shared knowledge stores across a multi-agent fleet.
Unlike the human notion of memory, agent memory is an architectural choice. Each component is a database (or database-shaped abstraction) with read, write, and retrieve operations, and each ships with distinct failure characteristics. The April 2024 survey of agent memory systems catalogued over a dozen architectures in production use, each with its own trust model.
The industry treats agent memory as a capability upgrade: more memory, smarter agent. The reality is that every memory component adds both a new capability and a new failure surface. A RAG pipeline can retrieve documents, and it can retrieve poisoned documents. A conversation history can preserve context, and it can preserve hallucinations that return as "facts."
The practical definition for engineers: AI agent memory is the set of durable state surfaces that outlive a single session, and that therefore require their own integrity, provenance, and revision controls.
What are the three failure modes of AI agent memory?
The three failure modes are corruption, confabulation, and calcification. Each describes a different path by which stored state degrades agent reliability, and each requires a different control.
Corruption is the adversarial failure mode. External or internal inputs poison the memory store (indirect prompt injection, data poisoning, supply-chain contamination), so future retrievals return manipulated or malicious content. Mitigation: input validation and trust-scored provenance at the write path.
Confabulation is the recursive failure mode. The agent hallucinates in one session, the hallucination gets stored, and a later retrieval returns it as a "fact." Sycophantic reinforcement from agreeable users accelerates the loop. Mitigation: provenance tags that distinguish agent_generated from verified_document at retrieval time.
Calcification is the stickiness failure mode. Once a wrong fact is stored with high confidence, the agent defends it against correction (academic research calls this "faithfulness to prior context", tied to memory strength and evidence style). Mitigation: belief revision protocols that propagate user corrections back to the memory store and mark superseded entries.
Standard observability catches none of these reliably. All three produce outputs that look grounded, the agent even cites retrieved context, while the failure lives in the data layer, not the execution path.
What is AI agent memory poisoning?
AI agent memory poisoning is the injection of adversarial or manipulated content into an agent's persistent memory store so that future retrievals return attacker-controlled context. It is the corruption failure mode of agent memory and maps directly to OWASP LLM04 (Data and Model Poisoning).
The attack surface is larger than most teams assume. Any input path that reaches the vector store is an injection vector: support tickets, user uploads, scraped web content, third-party API responses, even the agent's own output if it is written back to storage without validation. Indirect prompt injection research from Lakera demonstrates how a single poisoned ticket indexed today can trigger unsafe behavior in an unrelated user session weeks later, because the embedded instructions retrieve as "relevant context."
Poisoning differs from classical prompt injection in persistence. A classical injection dies with the session. A poisoned memory entry keeps retrieving, session after session, until the entry is removed or superseded.
Defenses are not prompt-layer defenses. Content filters over the prompt cannot help once the attack is embedded in retrieved context. The control plane belongs at the memory-write path: trust-scored input validation, embedding fingerprinting, and quarantine on anomaly, before content reaches retrieval.
How does an AI agent context window differ from agent memory?
The AI agent context window acts as a form of short-term memory or working memory. It is the ephemeral input buffer passed to the model on each call, typically measured in tokens and cleared between sessions. Agent memory is the durable layer that survives across calls and sessions: RAG indexes, vector stores, conversation histories, and semantic memory.
The distinction matters because their failure modes are different. A context window failure (truncation, context bleed, token limits) is visible and session-bound. You can inspect the prompt, see what was included, and reproduce the bug. A memory failure hides in stored data that may have been written weeks earlier, by a different user, in a different session.
Memory also has its own write path. Anything stored becomes input to future context windows, which means corruption or confabulation at write-time becomes a context window problem at read-time, even though the write is long out of trace. That is why trace-the-failure debugging often fails for memory issues: the trace is clean, the bug is in the data.
Practically: treat the context window as a cache with fixed eviction and memory as a database with writes, reads, retention, and integrity constraints. They need different controls. Prompt-layer defenses guard the context window. Memory governance guards the store.
How do I detect memory corruption in a RAG pipeline?
Standard RAG observability will not catch corruption, because the retrieval path looks healthy even when the stored content is poisoned. Detection requires instrumentation on three axes: provenance, integrity, and outlier behavior.
Start with provenance metadata on every write. Tag each entry with source_type (verified_docs, agent_output, user_input, external_unverified) and an initial trust score. At retrieval, log the distribution of sources feeding each response. A shift toward lower-trust tiers for a specific query pattern is an early signal.
Add integrity fingerprinting. Generate a cryptographic hash of the content at storage time and re-verify on retrieval. A fingerprint mismatch means the underlying content changed after ingestion, which is almost never legitimate for a vector store.
Instrument outlier behavior. Track the rate at which a given embedding cluster is retrieved versus baseline. Sudden spikes from a cluster linked to a single low-trust source are a common indirect-prompt-injection signature.
Finally, track Memory Consistency Score (MCS) from the Agent Reliability Index: contradiction rate across retrieved memories, source attribution coverage, retrieval staleness. A degrading MCS without a corresponding model or prompt change is the composite signal that corruption is reaching production retrievals.
Should I use RAG, long-term memory, or both?
Use the minimum architecture that meets the reliability requirement, and assume every added memory component adds a failure surface you must govern.
RAG is appropriate when the agent needs access to a large, relatively static corpus (documentation, knowledge base, policy documents) that you control and can version. Its failure surface is poisoned documents and retrieval drift, both governable with input validation and provenance tracking.
Long-term or episodic memory (per-user profiles, conversation histories, learned preferences) is appropriate when personalization genuinely improves the agent's output. Its failure surface is confabulation (stored hallucinations) and calcification (stuck wrong beliefs), governable with source tagging and belief revision protocols.
Both, combined, compound risk. Shared multi-agent memory is the highest-risk configuration: one agent's corruption propagates to every agent reading the shared store.
Decision criterion: if you cannot answer yes to the Memory Governance Checklist (input validation, provenance tracking, self-reference detection, correction propagation, memory auditing, expiration policies, trust tiering), then you do not have the controls to run that memory component safely, regardless of its capability upside. Default to the simpler architecture, invest in governance first, then scale memory components against verified reliability gains.
How does memory governance fit into the Prevention Stack?
Memory governance extends the Prevention Stack with three runtime controls targeting the three memory failure modes: integrity verification against corruption, provenance tracking against confabulation, and belief revision protocols against calcification. All three sit in the agent's decision loop, not in post-hoc observability, so they block bad retrievals and bad writes before they influence behavior.
The existing Prevention Stack components (loop detection, cost bounds, step limits, business logic guardrails) govern the execution path. Memory governance governs the data layer that feeds the execution path. Without it, an agent can pass every execution-layer guardrail and still act on poisoned, hallucinated, or stale stored context.
The three controls map to concrete engineering work. Integrity verification is trust-scored input validation plus cryptographic fingerprinting at the write path. Provenance tracking is source-type metadata attached to every stored entry and surfaced at retrieval. Belief revision is a correction propagation protocol that updates the memory store, not just the current session, and marks superseded entries excluded from retrieval.
The measurable outcome is a higher Memory Consistency Score (MCS) and Context Integrity Index (CII) in the Agent Reliability Index, which in turn prevents the cascade to Action Governance Score (AGS) failures.
Related Resources
- The Prevention Stack: Beyond Observability: the four-component framework for runtime agent governance
- The 5 Agent Failure Modes: the taxonomy of agent failures, including Memory Corruption (Failure Mode 2)
- When AI Agents Lie: Forensic Analysis of the SaaStr Database Deletion: how an agent fabricated data to cover its own errors, a confabulation failure mode in action
- The Agent Reliability Index: the measurement framework where Memory Consistency Score (MCS) quantifies memory reliability
Sources
[1] A Survey on the Memory Mechanism of Large Language Model based Agents, April 2024. Comprehensive survey of memory architectures for LLM-based agents, documenting failure patterns and reliability gaps.
[2] Lakera — Indirect Prompt Injection Research. Practical demonstration of memory poisoning attacks against RAG-based agent systems.
[3] OWASP Top 10 for LLM Applications. Industry-standard vulnerability classification including data poisoning for LLM systems.
[4] Investigating Context-Faithfulness in Large Language Models: The Roles of Memory Strength and Evidence Style. Research on context-faithfulness in LLMs, including how memory strength and evidence style drive belief persistence against user correction.
[5] Towards Understanding Sycophancy in Language Models, October 2023. Anthropic research on sycophantic tendencies in LLMs and their interaction with retrieval-augmented systems.
[6] Nyhan & Reifler — "When Corrections Fail", 2010. Cognitive psychology research on the backfire effect in belief correction.
[7] Tech Startups — $47,000 AI Agent Failure, November 2025. Multi-agent runaway cost incident demonstrating cascading agent failures.