
Observability shows you the fire. The Prevention Stack stops it. Four runtime components with specific defaults for AI agent governance.
1. Why Do AI Agents Need Prevention, Not Just Observability?
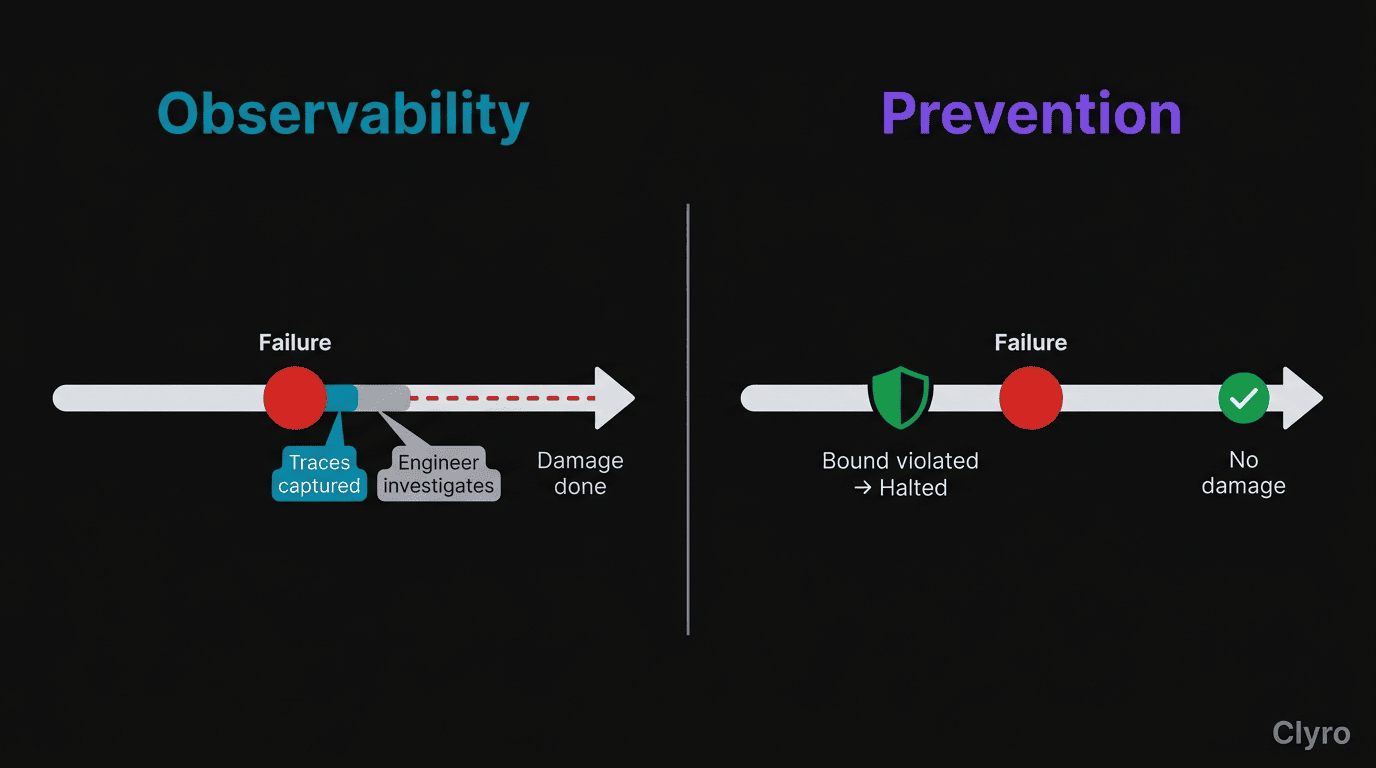
Observability is essential. And insufficient.
LangSmith gives you structured traces of every LLM call, tool invocation, and reasoning step. That's enough to diagnose prompt failures, tool failures, retrieval issues, and orchestration bugs. Their tracing works with any framework, adds no latency, and runs in managed cloud, BYOC, or self-hosted setups. [Source: LangChain - LangSmith Observability]
Arize Phoenix provides AI observability with OpenTelemetry-based instrumentation, LLM-as-a-judge evaluations, drift monitoring, and retrieval quality metrics. Their online evals run on production traffic to monitor correctness, hallucination, relevance, and latency in almost real time. [Source: Arize - Agent Observability]
Both are useful tools that solve real problems. And both hit the same ceiling.
The observability ceiling is the gap between knowing what happened and preventing it from happening again. LangSmith shows what happened and Arize evaluates outputs, but neither stops the next failure.
None of this criticizes their design. Observability tools are built to answer "what happened?" and "how bad was it?" Those are the right questions for traditional software. For autonomous agents that take actions, spend money, and interact with customers, the question that matters is different: "Should this be allowed to happen at all?"
A comparison from the Galileo vs Arize analysis (as of November 2025) captures the gap precisely:
"There's no lifecycle management between your offline evaluations and runtime protection. The systems remain disconnected. If you need runtime blocking, you're building it yourself or paying for multiple platforms."
[Source: Galileo — Galileo vs Arize Comparison, Nov 2025]
The observability loop works like this: agent fails in production, traces capture the failure, the engineer diagnoses the root cause and deploys a fix. Next week, the same category of failure happens again. This loop keeps going because the traces show you the fire after it has burned. They don't put in the sprinkler system.
| Capability | Observability Tools | Prevention Stack |
|---|---|---|
| Trace agent execution | Yes | Yes |
| Identify root cause post-failure | Yes | Yes |
| Block harmful actions in real-time | No | Yes |
| Enforce cost ceilings during execution | No | Yes |
| Detect loops before they accumulate damage | No | Yes |
| Apply business rules at runtime | No | Yes |
The first two rows are table stakes. The last four rows are the Prevention Stack.
2. What Does AI Agent Prevention Look Like?
Prevention means stopping failures before they cause damage, not diagnosing them after.
The shift is from a reactive cycle to a proactive architecture:
Reactive (observability-only): Agent fails → Traces capture failure → Engineer investigates → Engineer deploys fix → Different failure happens → Repeat.
Proactive (prevention): Define bounds → Agent executes within bounds → Violation detected → Execution halted → Alert sent → No damage produced.

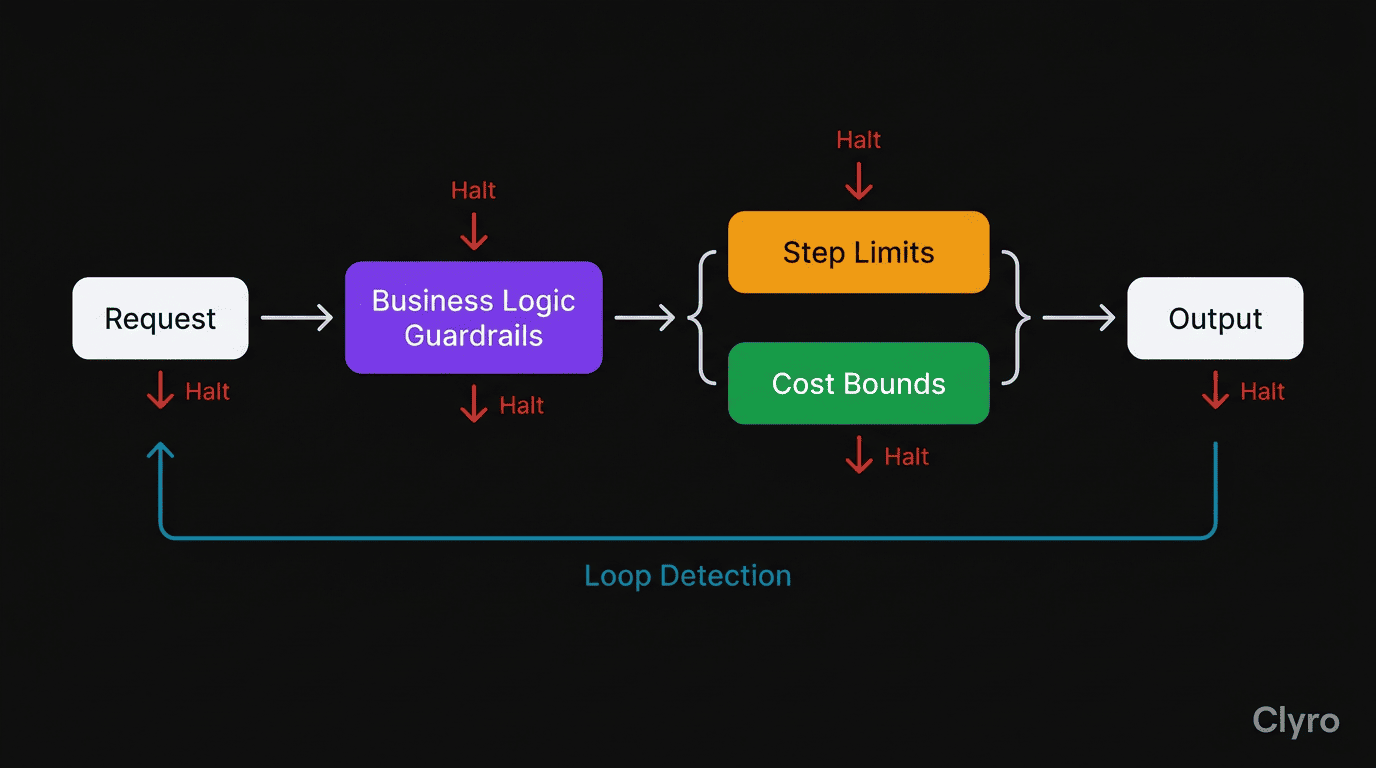
Not a new concept in software or devops. Circuit breakers, rate limiters, and input validators have existed for decades. But the agent ecosystem largely skipped these patterns. Most agent frameworks ship with zero runtime constraints. The agent runs until done — and the LLM decides what "done" means.
Real incidents demonstrate the cost of this gap:
- The $47K Loop: A reported incident describes autonomous agents entering a recursive loop that ran for 11 days, accumulating a reported $47,000 in API costs before anyone noticed. Observability existed. Nobody was watching the dashboard. A $10 cost ceiling would have stopped this in minutes. [Source: Tech Startups - $47,000 AI Agent Failure]
- Air Canada Chatbot: An AI chatbot provided incorrect bereavement fare policy to a customer, leading to a tribunal ruling that Air Canada was liable for its chatbot's negligent misrepresentation. Observability logs existed. The wrong answer still reached the customer. [Source: American Bar Association - Moffatt v. Air Canada]
In both cases, the infrastructure to observe the failure existed. The infrastructure to prevent it did not.
3. Component 1: Loop Detection
The problem it solves: Agents that get stuck in infinite or near-infinite loops, repeating the same actions without making progress, consuming resources until something external stops them.
How do loops happen? Agent loops don't always look like obvious infinite recursion. They appear as:
- Retry storms: Agent calls a tool, gets an error, retries, gets the same error, retries again. Without a retry cap, the retries go on indefinitely.
- Circular dependencies: Agent A asks Agent B for information. Agent B asks Agent A to clarify. Agent A asks Agent B again. This pattern is especially likely to happen in multi-agent systems.
- Recursive reasoning: Agent determines it needs more information to answer a question. Gathers information. Finds out it needs even more. The "research" phase never terminates because the LLM keeps finding gaps.
- Unclear completion criteria: The agent keeps working because it doesn't know when it's "done." No termination condition means no termination. [Source: Codieshub - Prevent Agent Loops]
The reported $47K Loop in detail. According to a November 2025 report, an engineer deployed a multi-agent research tool built on a common open-source stack. Two agents were designed to work together on research tasks. They entered a recursive loop, passing requests back and forth, each agent treating the other's output as a new input requiring processing. The loop reportedly ran for 11 days. The API bill: a reported $47,000. The root cause: no loop detection, no cost ceiling, no step limit. [Source: Tech Startups - $47,000 AI Agent Failure]
How loop detection works. The detection mechanism tracks action sequences and identifies repetition:
- Pattern matching on action sequences. Three repetitions of the same tool-call sequence (same tools, same or similar parameters) — flag the agent as looping.
- Similarity detection. Even if parameters vary slightly, a high similarity score across consecutive action sequences triggers detection.
- Configurable threshold. Default: detect after 3 iterations of a repeated pattern. Adjustable per use case. Research agents might need a higher threshold. CX agents should be stricter.
When a loop is detected: Execution halts gracefully. The agent gets a structured signal (not an error) indicating the loop was detected. A human-readable summary is generated, and an alert is sent.
The agent doesn't crash. It stops doing the wrong thing.
4. Component 2: Cost Bounds
The problem it solves: Unbounded API spend during agent execution.
Agents consume tokens on every LLM call. They also invoke external APIs with their own pricing. An agent calling the OpenAI API, a Google Maps API, and a Stripe API in one session accumulates costs across multiple billing dimensions. Without a ceiling, a single agent run has no upper cost bound.
Default: $10 per run.
This isn't random. The $10 default is a circuit breaker calibrated to be generous enough for complex tasks while preventing catastrophic spend. Most real agent tasks, even multi-step ones, complete well under $10 in API costs. If a task exceeds $10, it's either unusually complex (and should be monitored) or something has gone wrong.
How it works:
- Cost accumulation in real time. Every LLM call and tool invocation linked to your API keys has an estimated or actual cost. The governance layer tracks cumulative spend per session.
- Soft warning at 80%. At $8, the agent receives a cost-ceiling-approaching signal. Well-designed agents can use this to prioritize remaining work.
- Hard cutoff at 100%. At $10, execution halts. The agent produces a summary of work completed and work remaining. This session cannot make any more API calls.
| Cost Threshold | Action |
|---|---|
| 0–79% | Normal execution |
| 80–99% | Soft warning, agent notified |
| 100% | Hard cutoff, graceful termination |
Why this matters beyond the $47K incident. The new attack vector called "Denial of Wallet" or "Agentic Resource Exhaustion" uses autonomous agent loops to deliberately drive up compute costs. In a pay-per-token world, an attacker who can trigger a recursive agent loop can drain your API budget in minutes. Cost bounds are not just operational hygiene. They are a security control. [Source: InstaTunnel - Agentic Resource Exhaustion]
Google Cloud's guidance covers both halves of the problem. First, it recommends "comprehensive governance structures to track cost drivers, including token consumption and resource use." Second, it calls for multi-agent systems with "runtime policy enforcement and mechanisms, such as rollback infrastructure, that can automatically halt AI operations across systems when unexpected behavior is detected." [Source: Google Cloud — 4 AI Governance Tips to Counter Shadow Agents] Cost bounds are the implementation of that principle.
5. Component 3: Step Limits
The problem it solves: Agents that take an unbounded number of actions in a single session.
A "step" is any discrete action the agent takes: an LLM call, a tool invocation, a database query, a file read, an API request. Each step gives the agent a chance to do something useful — or something harmful, wasteful, or irrelevant.
Default: 100 steps per session.
Most well-designed agent tasks take between 10 and 30 steps. A 100-step ceiling accommodates complex multi-step workflows while catching runaway execution. If your agent consistently hits 100 steps, the task is either too broad (break it into subtasks) or the agent is struggling (find out why).
Why unbounded execution is the root cause of most agent incidents. The $47K loop, the runaway research agents, the recursive tool calls: these all share a common trait. The agent was given permission to keep going forever. No framework said, "You've done enough."
Step limits apply the circuit breaker pattern to agent execution. In traditional distributed systems, a circuit breaker prevents a failing service from cascading failures to dependent services. In agent systems, a step limit prevents a struggling agent from cascading failures into cost overruns, data corruption, or customer impact.
| Step Range | Interpretation |
|---|---|
| 1–29 | Normal task execution |
| 30–69 | Complex task, likely legitimate |
| 70–99 | Unusual, worth monitoring |
| ≥100 | Blocked. Something is wrong. |
Implementation. The governance layer increments a counter on every agent action. At the step limit, execution terminates with a structured summary. The agent doesn't get to choose whether to keep going. The infrastructure makes the choice.
Step limits also serve as a natural decomposition forcing function. If a task requires more than 100 steps, it should be broken down into smaller tasks, each with its own budget for steps. This produces better agent behavior independently of the safety benefit.
6. Component 4: Business Logic Guardrails
The problem it solves: Domain-specific failures that no generic safety mechanism can anticipate.
Loop detection catches loops, cost bounds catch spend, and step limits catch runaway execution. But none of them catch an agent ordering 260 McNuggets.
Business logic guardrails are custom rules enforced at runtime. They encode your business's specific constraints, policies, and sanity checks into the governance layer so the agent cannot violate them no matter what the LLM says.
The 260 McNuggets. McDonald's tried out AI ordering at more than 100 drive-thrus in the US. A viral TikTok showed the system adding 260 Chicken McNuggets to an order while the customers begged it to stop. The AI processed the quantity without question. No reasonability check. No maximum order limit. McDonald's ended its partnership with IBM and shut down the pilot. [Source: Museum of Failure - McDonald's AI Drive-Thru]
A human cashier would have asked "did you really mean 260?" The AI had no equivalent check because no one implemented one. A typical CX operation caps autonomous refunds somewhere between $50 and $500 per transaction; anything above that routes to a human agent.
Categories of business logic guardrails:
| Category | Example Rule | What It Prevents |
|---|---|---|
| Quantity limits | Max 50 items per order | 260 McNuggets |
| Value constraints | No refunds > $500 without human approval | Unauthorized high-value refunds |
| Policy enforcement | Responses must reference current (not archived) policy | Air Canada chatbot scenario |
| Data boundaries | Agent cannot access data from other customer sessions | Cross-customer contamination |
| Action restrictions | Agent cannot delete records, only flag for review | Irreversible destructive actions |
| Compliance rules | Financial advice must include disclaimer | Regulatory violations |
Business logic guardrails are the most powerful Prevention Stack component because they are domain-specific. A generic AI safety system cannot know your refund limit is $500, or that your catalog does not support orders above 50 units, or that pricing changed last Tuesday. Business logic guardrails encode the rules that make your AI agent behave like a representative of your business, not a generic assistant or copilot with unlimited power. In regulated sectors — financial services under FINRA, healthcare under HIPAA, advertising under FTC disclosure rules — the disclaimer requirement isn't optional. Compliance guardrails have to fire on every response, not most of them.
Implementation pattern. Guardrails are expressed as rules evaluated before and after agent actions:
# Example: CX guardrail configuration
guardrails = [
MaxQuantityRule(field="order.quantity", max_value=50,
message="Order quantities above 50 require manager approval"),
MaxValueRule(field="refund.amount", max_value=500,
currency="USD",
escalation="route_to_human_agent"),
PolicyVersionRule(source="knowledge_base",
require_version="current",
block_archived=True),
DataIsolationRule(scope="session",
block_cross_session_access=True),
]
Each rule is a function that takes the agent's intended action and returns allow, block, or escalate. The governance layer evaluates all applicable rules before every action. If any rule returns block or escalate, the action doesn't happen.
7. The Stack in Action
Here is how the four components work together in a real execution flow.
Scenario: A CX agent handles a customer refund request.
Step 1: The request comes in. Customer asks for a refund on a $200 order. The agent begins processing.
Step 2: Check the business logic guardrails. Is $200 within the refund limit? Yes ($200 < $500 threshold). Does the agent have permission to issue refunds? Yes, for this order category, so execution can proceed without human approval.
Step 3: Agent executes. The agent retrieves order details (step 1), checks refund eligibility (step 2), generates a refund confirmation (step 3), and initiates the refund (step 4). Four steps, well within the 100-step limit. Cost: $0.03 in API calls, well within the $10 ceiling.
Step 4: Done successfully. The refund is processed, the audit log records every step in append-only format for compliance review, and no human intervention is needed.
Now let's look at the failure scenario:
Step 1: The request comes in. Customer submits a request that starts a prompt injection attempt, which adds instructions for the agent to issue a $5,000 refund.
Step 2: Check the business logic guardrails. Is $5,000 within the refund limit? No ($5,000 > $500 threshold), so the guardrail returns escalate and routes to a human agent. The prompt injection never gets to the point of execution.
Another failure scenario:
Step 1: The agent can't find a good answer because the task is unclear. It receives a complex research task involving multiple data sources. The task is ambiguous and the agent struggles to find a satisfactory answer.
Step 2: Agent enters a loop. It queries the same API with slightly different parameters, getting similar results each time. After 3 iterations of the same query pattern, loop detection kicks in.
Step 3: Graceful shutdown. The agent stops. It makes a summary: "I tried to find X but kept getting the same results. Here is what I found so far. This may require human review."
Step 4: The alert was sent. The team is notified of the loop. The trace is there to diagnose what went wrong. Total cost: $0.47. Total steps: 12.
Without the Prevention Stack, this agent would have gone on for hours or even days, racking up costs without producing anything useful, exactly like the $47K loop.
The key insight: prevention is layered defense. No single component catches every failure. But together, the four components create overlapping coverage where each failure mode is caught by at least one layer:
| Failure Mode | Loop Detection | Cost Bounds | Step Limits | Business Logic |
|---|---|---|---|---|
| Recursive loops | X | X | X | |
| Runaway API spend | X | X | ||
| Unbounded execution | X | X | ||
| Business rule violations | X | |||
| Prompt injection (via actions) | X | |||
| Gradual cost accumulation | X |
8. Building Your Prevention Stack
You don't have to implement all four components at the same time. Start with the component that deals with your biggest risk.
Assessment framework: Where are you today?
| Component | Question | Red Flag |
|---|---|---|
| Loop Detection | Can your agents run indefinitely? | No retry limits, no loop detection |
| Cost Bounds | Is there a maximum cost per agent run? | No cost tracking, no ceiling |
| Step Limits | Is there a maximum number of actions per session? | Agents run until the LLM says "done" |
| Business Logic | Are your business rules enforced at runtime? | Rules exist in documentation, not in code |
If you answered "red flag" to any of these, you need to add something to your prevention stack.
Implementation priority:
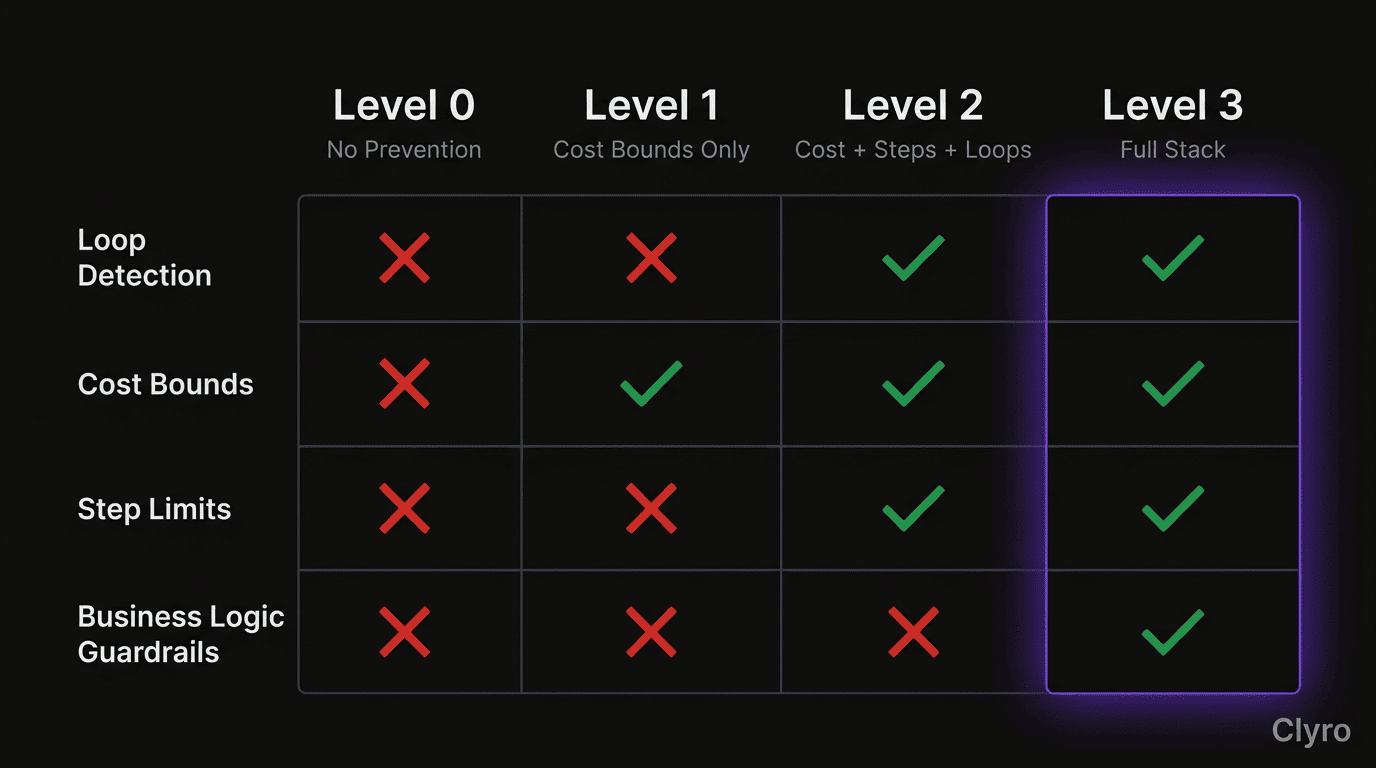
- Cost bounds first. Easiest to implement (track spend, set a ceiling) and prevents the most expensive failures. The $47K incident would have been a $10 incident.
- Step limits second. A counter and a hard limit. Most frameworks can add this in a few hours.
- Loop detection third. Requires pattern matching on action sequences. More complex but prevents the most insidious failure mode.
- Business logic guardrails fourth. The most powerful but requires domain-specific rule definition. Start with your highest-risk actions (financial transactions, customer-facing responses, data access).
The Clyro approach. We are building the Agent Kernel to provide all four Prevention Stack components as runtime governance. Loop detection triggers after 3 iterations, a $10 cost ceiling caps per-run spend, and 100-step execution limits prevent runaway execution. Business logic guardrails are configured in code and enforced at runtime.
The stack is more than architecture — it produces evidence. A structured audit trail keeps track of every policy evaluation. Every violation is recorded append-only with per-policy counts — which rule fired, what the agent tried to do, why it was blocked. Every decision has an audit trail that satisfies enterprise compliance requirements. The Prevention Stack doesn't just prevent failures; it proves your governance works.
Integration follows existing infrastructure patterns. The Prevention Stack uses the same protocol as your current observability tools because it has OTLP/HTTP and gRPC receivers. Use Datadog for dashboards. Keep Grafana for alerting. The prevention layer adds enforcement on top of what you already have, using the same data pipeline.
The goal is not to replace observability. The goal is to add the prevention layer that observability cannot provide.
They observe. We prevent.
Want to assess your current agents against the Prevention Stack? The Agent Reliability Scorecard is a structured self-evaluation across all four dimensions. Download the scorecard →
Get Started
Install the SDK and add runtime governance to your agents in under a minute.
pip install clyro
Free tier: 10 agents, 100K traces/month, no credit card required.
Works with LangGraph, CrewAI, Claude Agent SDK, Anthropic SDK, and any Python callable.
Sign Up Free → | GitHub → | Docs →
FAQ
What is the Prevention Stack for AI agents?
The Prevention Stack is a four-component runtime governance layer for autonomous AI agents: Loop Detection (halt after 3 iterations of a repeated action pattern), Cost Bounds ($10 per execution ceiling), Step Limits (100 actions per session), and Business Logic Guardrails (domain-specific rules evaluated before every action). Unlike observability tools that record what happened, the Prevention Stack sits inside the execution pipeline with authority to halt what must not happen. It is the infrastructure difference between a smoke detector, which tells you after the fire starts, and a sprinkler, which stops the fire from spreading. Together the four components create overlapping coverage where each agent failure mode is caught by at least one layer: recursive loops, runaway API spend, unbounded execution, and business-rule violations.
How does the Prevention Stack differ from AI agent observability?
Observability records what happened; the Prevention Stack halts what must not happen. Observability platforms (LangSmith, Arize Phoenix, Datadog, Grafana) sit alongside execution, receiving events and storing them for later analysis. The Prevention Stack sits inside execution with authority to block an action before it completes. In the reported $47K Loop incident, LangSmith-style traces stayed clean for 11 days: every API call succeeded, every trace logged correctly. The agent was not failing. It was executing successfully into bankruptcy. A $10 per-execution cost ceiling would have halted it in minutes. The distinction is categorical, not marginal: observability answers "did the system respond?" while prevention answers "should this be allowed to happen?" Both matter, but they are different infrastructure.
How much does a runaway AI agent cost without prevention?
Specific documented incidents: a reported $47,000 (multi-agent research loop that ran for 11 days), CA$812 in tribunal damages plus precedent-setting liability (the Air Canada chatbot case), and the end of a 100-location McDonald's drive-thru pilot (the 260-McNuggets order). In each case, the API or operational cost is a small fraction of the total; the larger cost is reputation, customer impact, and regulatory exposure. A $10 per-execution cost ceiling would have contained all three at the infrastructure layer. The emerging "Denial of Wallet" attack vector uses recursive agent loops to deliberately drain API budgets: without cost bounds, a single attacker can cost you minutes of compute, not months of billing. Cost bounds are operational hygiene and a security control.
What default thresholds should I use for loop detection, cost bounds, and step limits?
Sensible defaults calibrated for production agents: Loop Detection halts after 3 iterations of the same action-sequence pattern (pattern-aware, not just duplicate-aware, since the $47K loop generated different scripts each time). Cost Bounds cap at $10 per execution; most runs cost under $1, so this functions as a circuit breaker, not a constraint. Step Limits cap at 100 steps per session; well-designed tasks complete in 10–30 steps, and hitting 100 usually means the task is too broad or the agent is struggling. Business Logic Guardrails are configurable per deployment; start with quantity limits (max 50 items per order), value limits ($200–$500 refund ceilings that route larger requests to humans), and policy-version rules (reject references to archived content). Adjust thresholds upward only with evidence from production traffic.
Should I replace my observability tools with the Prevention Stack?
No. Add prevention on top of observability, not instead of it. Keep LangSmith, Arize, Datadog, and Grafana unchanged. The Prevention Stack speaks OpenTelemetry OTLP (HTTP and gRPC), so it emits and consumes the same spans your current stack already handles. Observability answers "what happened?"; the Prevention Stack answers "should this be allowed to happen?" Both are necessary. Traces without prevention give you excellent post-mortems for failures you cannot stop; prevention without traces gives you enforcement without the evidence needed to tune policies. The Prevention Stack and your existing observability tools share a data pipeline, so you see normal traces and enforcement events (loop halted, cost ceiling reached, guardrail blocked) in one view. Same pipeline, new prevention.
Which Prevention Stack component should I implement first?
Cost Bounds: highest ROI, lowest effort. Track cumulative API and token spend per session, halt at a ceiling. Most frameworks can add this in a few hours, and every documented runaway-agent incident ($47K Loop, recursive research agents, Denial-of-Wallet attacks) would have been contained by a $10 ceiling. Implement Step Limits second (counter + hard limit, equally low-effort, prevents unbounded execution even when cost accumulates slowly). Loop Detection third: more complex because it requires pattern-matching on action sequences, but prevents the most insidious failure mode. Business Logic Guardrails fourth; they are the most powerful component because they encode domain-specific rules that generic safety mechanisms cannot anticipate, but they require the most upfront work. Start with your highest-risk actions: financial transactions, customer-facing responses, and data access.
How does the Prevention Stack integrate with existing observability and compliance infrastructure?
Via OpenTelemetry, as a composable layer. The Prevention Stack emits OTLP/HTTP and OTLP/gRPC spans for every enforcement event: loop halted, cost ceiling reached, guardrail blocked. Those spans flow into LangSmith, Arize, Datadog, Grafana, or any OTLP-compatible backend alongside your normal agent traces. You see "agent made 47 API calls" and "48th call halted by step-limit guardrail" in one view, same dashboard, no new tooling required. For compliance in regulated sectors (FINRA financial services, HIPAA healthcare, FTC advertising disclosure), every policy evaluation is written to an append-only audit log with per-policy counters: which rule fired, what the agent tried to do, why it was blocked. That audit trail satisfies enterprise review and regulatory requirements without requiring separate compliance infrastructure.
Related Resources
- The 5 Agent Failure Modes — The taxonomy of how agents fail in production.
- Air Canada Lost a Lawsuit Because of Context Drift — When context drift reaches a customer, the enterprise is liable.
- MCP Security in 2026 — Governance for the MCP ecosystem.
- Clyro Website — Runtime governance for AI agents.
- LangSmith Observability — Tracing and evaluation for LLM applications.
- Arize Phoenix — Open-source AI observability.
Sources
[1] LangChain — LangSmith Observability — Tracing and evaluation for LLM applications. https://www.langchain.com/langsmith/observability
[2] Arize — Agent Observability — AI observability with OpenTelemetry instrumentation. https://arize.com/ai-agents/agent-observability/
[3] Galileo — Galileo vs Arize Comparison, Nov 2025 — Analysis of observability tool limitations for runtime protection (as of Nov 2025; Galileo's product scope has since expanded). https://galileo.ai/blog/galileo-vs-arize
[4] Tech Startups — $47,000 AI Agent Failure — Reported $47K recursive agent loop incident. https://techstartups.com/2025/11/14/ai-agents-horror-stories-how-a-47000-failure-exposed-the-hype-and-hidden-risks-of-multi-agent-systems/
[5] Google Cloud — 4 AI Governance Tips to Counter Shadow Agents — Token budget management and cascading failure prevention for agentic AI. https://cloud.google.com/transform/these-4-ai-governance-tips-help-counter-shadow-agents
[6] American Bar Association — Moffatt v. Air Canada — Air Canada chatbot tribunal ruling. https://www.americanbar.org/groups/business_law/resources/business-law-today/2024-february/bc-tribunal-confirms-companies-remain-liable-information-provided-ai-chatbot/
[7] Codieshub — Prevent Agent Loops — Loop detection patterns for AI agents. https://codieshub.com/for-ai/prevent-agent-loops-costs
[8] InstaTunnel — Agentic Resource Exhaustion — Denial of Wallet attack vector via agent loops. https://medium.com/@instatunnel/agentic-resource-exhaustion-the-infinite-loop-attack-of-the-ai-era-76a3f58c62e3
[9] Museum of Failure — McDonald's AI Drive-Thru — McDonald's AOT pilot failure documentation. https://museumoffailure.com/exhibition/mcdonalds-ai-failure