What is the agent kernel? The missing infrastructure layer every AI agent deployment needs for runtime governance, execution bounds, and reliability.
1. The Pattern
An AI agent doesn't just answer questions — it takes actions. It calls APIs, places orders, modifies databases, sends emails, executes code. That autonomy is what makes agents valuable. It is also what makes ungoverned agents dangerous in a way that a bad model output simply isn't: a wrong answer can be corrected, but a wrong action may already have cleared.
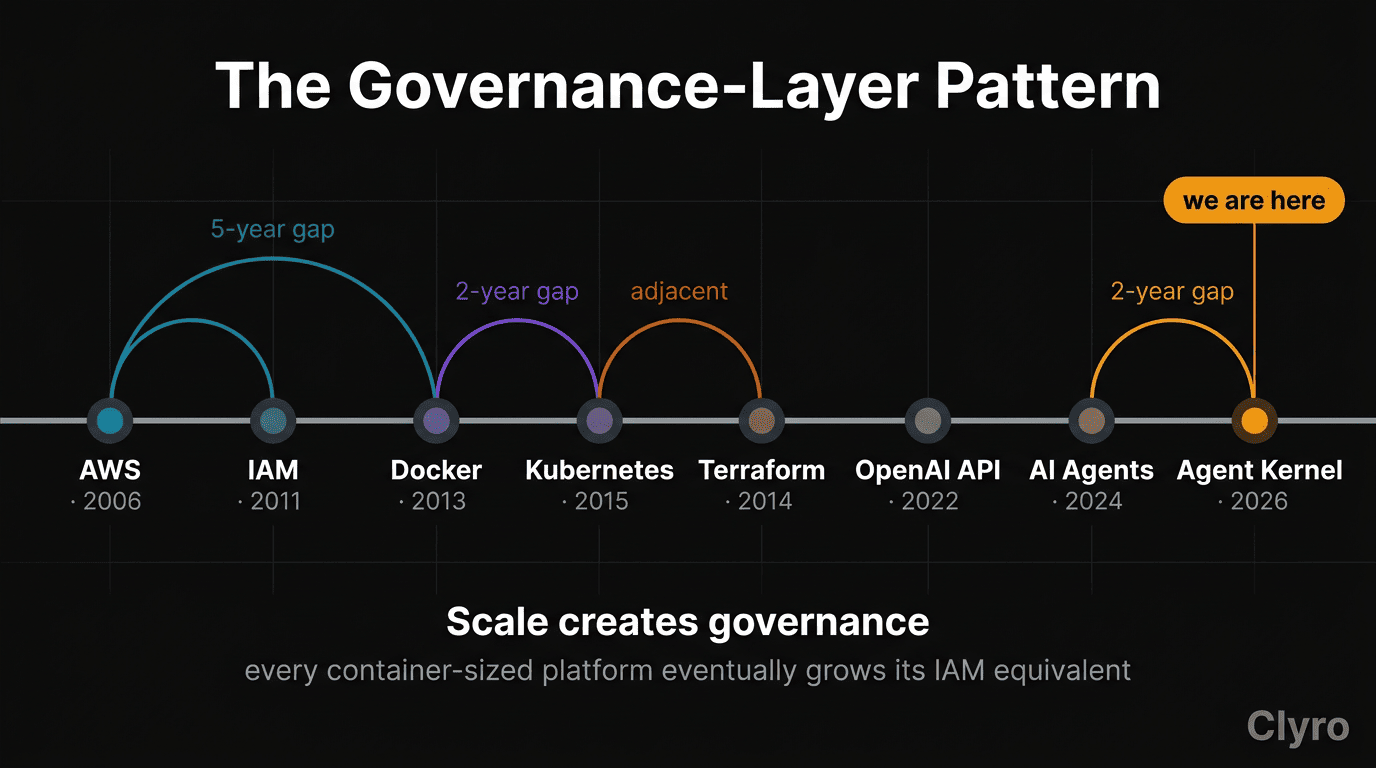
The same problem has appeared before, in three other infrastructure transitions. A transformative technology emerges. Early adopters prove it works. Enterprises try to deploy it. And then everything stalls — not because the technology is broken, but because the governance layer doesn't exist yet.
Cloud computing → IAM. AWS launched in 2006. For five years, cloud services worked and adoption grew. But enterprise IT teams could not answer a fundamental question: who has access to what? Without centralized identity and access management, every cloud deployment was a security and compliance risk. AWS IAM launched in 2011, five years after the cloud services it governed. [Source: AWS — Happy 10th Birthday IAM] Today, IAM handles over 400 million API calls per second worldwide. The technology it governs has not changed. The ability to govern it created the enterprise cloud market.
Containers → Kubernetes. Docker made containers practical in 2013. Within a year, companies were running containers in production. Within two years, they were drowning: no orchestration, no service discovery, no lifecycle management, no way to run containers at scale without a team of engineers writing custom tooling. Google released Kubernetes 1.0 in July 2015, donating it to the Cloud Native Computing Foundation. [Source: Kubernetes Blog — 10 Years of Kubernetes] Containers worked before Kubernetes. Kubernetes made them deployable.
Infrastructure provisioning → Terraform. AWS CloudFormation existed. Manual provisioning scripts existed. But provisioning was cloud-specific, stateless, and ungoverned, meaning every deployment was a manual, error-prone process. HashiCorp released Terraform 0.1 in July 2014, introducing declarative, cloud-agnostic infrastructure-as-code with state management. [Source: HashiCorp — The Story of Terraform] By 2016, Terraform had over 750 contributors and dozens of cloud providers. The infrastructure worked before Terraform. Terraform made it governable.
The pattern is always the same:
| Phase | What Happens |
|---|---|
| 1. Technology works | Early adopters prove value |
| 2. Adoption accelerates | More teams deploy to production |
| 3. Governance gap emerges | Security, reliability, and compliance become blockers |
| 4. Governance layer appears | A unified infrastructure layer fills the gap |
| 5. Enterprise adoption follows | The governance layer, not the technology, unlocks scale |
AI agents are at Phase 3.
For agents, Phase 3 looks like this: two autonomous agents loop for eleven days and generate $47,000 in API costs before anyone notices. A food-ordering AI accepts a single transaction for 260 Chicken McNuggets. An airline chatbot cites a bereavement refund policy that was discontinued months earlier — and a court holds the airline liable. The technology worked. The governance layer didn't exist.
2. Why Agents Need a Kernel
The AI agent market hit $7.63 billion in 2025 and is projected to reach $10.91 billion in 2026. [Source: DemandSage — AI Agents Market Size] Gartner predicts 40% of enterprise applications will feature task-specific AI agents by 2026, up from less than 5% in 2025. [Source: Gartner Press Release, August 2025]
And yet: 95% of enterprise AI agent projects fail to reach production. [Source: MIT/Fortune, August 2025] Gartner predicts over 40% of agentic AI projects will be canceled by 2027 due to escalating costs, unclear business value, or inadequate risk controls. [Source: Gartner Press Release, June 2025]
The technology works. Adoption is accelerating. And the governance gap is wide open.
The current landscape is fragmented. Teams cobble together pieces of the governance layer from different tools, each covering a slice of the problem:
Observability tools (LangSmith, Arize Phoenix) provide tracing, debugging, and evaluation. LangSmith gives you structured traces of every LLM call, tool invocation, and reasoning step. Arize provides drift monitoring and LLM-as-a-judge evaluations on production traffic. Both are good tools. Both solve real problems. And both hit the same ceiling: they show you what happened after it happened. They do not prevent the next failure.
Guardrails (Guardrails AI, NVIDIA NeMo Guardrails) validate inputs and outputs. They check prompts before they reach the model and filter responses before they reach the user. This catches some failure modes, but guardrails evaluate messages statically. They cannot consider runtime context like accumulated cost, iteration count, or current system state when an agent is mid-execution.
Control planes (Microsoft Agent 365, Kore.ai) provide agent orchestration and management. They handle deployment, routing, and lifecycle. But they are platform-specific and typically lack the runtime enforcement layer that stops an agent from burning $47,000 in API costs or ordering 260 McNuggets.
The problem is not that these tools are bad. Each solves its piece well. The problem is that no unified layer sits beneath all of them. We built Clyro to be that layer: the Agent Kernel.
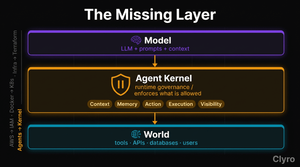
The Agent Kernel is the unified infrastructure layer that provides runtime governance for AI agents. It is not an observability tool (though it provides visibility). It is not a guardrail (though it enforces boundaries). It is not an orchestrator (though it manages execution). It is the foundational layer that connects all of these concerns into a coherent whole. A traditional OS kernel connects memory management, process scheduling, I/O, and security modules into a single essential core. The Agent Kernel plays that role for agents.
The key difference: an OS kernel is static. The Agent Kernel learns. It adapts defaults based on observed agent behavior, identifies emerging failure patterns, and compounds intelligence over time. This is why the name "kernel" fits better than "control plane" or "governance layer": it captures both the foundational nature and the intelligence that makes it distinct.
3. The Two Layers
The Agent Kernel has two layers, and the distinction matters because they deliver value on different timescales.
The Runtime Layer: Day-One Value
The Runtime Layer provides immediate, deterministic governance. It is the part of the kernel that ships with sensible defaults and works from the first agent execution.
| Component | What It Does | Default |
|---|---|---|
| Loop detection | Detects repeated action patterns and halts execution before loops accumulate damage | Triggers after 3 repeated iterations |
| Cost bounds | Enforces hard ceilings on token spend and API costs per session | $10 per session |
| Step limits | Caps the number of actions an agent can take in a single run | 100 steps per execution |
| Business logic guardrails | Enforces domain-specific rules at runtime (quantity limits, policy compliance, approval workflows) | Configurable per use case |
These are not suggestions. They are enforced boundaries. When an agent hits a loop, execution halts. When cost exceeds the ceiling, the session terminates. When a step limit is reached, the agent stops. When a business rule is violated, the action is blocked.
The defaults are specific because specificity is the point. "Intelligent loop detection" means nothing. "Loop detection after 3 iterations" means an engineer can evaluate whether that default fits their use case and adjust it. These four components form the Prevention Stack: the runtime enforcement layer that stops failures before they produce damage.
What the Prevention Stack would have prevented:
- The $47K Loop: a $10 cost ceiling stops this in minutes, not 11 days
- The 260 McNuggets: a quantity limit guardrail catches
qty > 50before the order submits - The Air Canada ruling: a policy compliance guardrail ensures responses match current policy, not hallucinated policy
The Intelligence Layer: Compounding Value
The Intelligence Layer operates on a longer timescale. It observes patterns across agent executions and uses them to improve governance over time.
| Capability | What It Does |
|---|---|
| Adaptive defaults | Adjusts loop thresholds, cost ceilings, and step limits based on observed agent behavior profiles |
| Drift detection | Identifies when agent behavior changes over time: output quality degradation, increasing cost patterns, shifting tool usage |
| Anomaly identification | Flags executions that deviate from established baselines: unusual tool call sequences, unexpected cost spikes, novel error patterns |
| Cross-agent learning | Applies patterns learned from one agent's failures to prevent similar failures in other agents |
The Runtime Layer stops the fire. The Intelligence Layer installs the smoke detector that learns where fires start.
This two-layer architecture is what separates the Agent Kernel from both observability tools (which provide visibility without enforcement) and static guardrails (which provide enforcement without intelligence). The Runtime Layer gives you day-one safety. The Intelligence Layer gives you compounding reliability.
4. The Five Capabilities
Each layer in the kernel governs through five specific capabilities — one for each category of production failure the Runtime and Intelligence layers are designed to prevent.

4.1 Context Intelligence
The failure it prevents: Agents operating on stale, incomplete, or irrelevant context, leading to hallucinated responses, incorrect actions, and eroded user trust.
Air Canada's chatbot cited a bereavement policy that no longer existed. The model was not hallucinating in the traditional sense. It was operating on context that was stale. The agent had no mechanism to verify that the information it referenced was current. [Source: ABA — Moffatt v. Air Canada]
What the kernel provides: Context validation, freshness verification, and relevance scoring. The agent always has the right information, or it knows it does not and says so.
4.2 Memory Integrity
The failure it prevents: Agents that confabulate memories, treat hypotheticals as facts, or accumulate contradictory information across sessions.
In multi-session agents, memory corruption is insidious. An agent discusses a hypothetical scenario in session 3, then in session 7 treats it as an established fact. Without memory integrity governance, there is no mechanism to distinguish between grounded memories and confabulated ones.
What the kernel provides: Memory grounding, consistency verification, and contradiction detection. Memories are facts, not confabulations.
4.3 Action Governance
The failure it prevents: Agents that take actions outside their intended boundaries: placing orders they should not place, accessing data they should not access, making commitments they are not authorized to make.
A fast-food AI ordering system accepted an order for 260 Chicken McNuggets and 4 McFlurries in a single transaction. No quantity limits existed. No business logic validated whether the order was reasonable. The agent processed it because nothing told it not to. [Source: [The 260 McNuggets incident — documented across DoorDash/McDonald's AI ordering reports]]
What the kernel provides: Policy enforcement, permission boundaries, and approval workflows. Agents act within defined boundaries, or they escalate to a human who can authorize the exception.
4.4 Execution Reliability
The failure it prevents: Runaway execution. Infinite loops, escalating costs, agents that run indefinitely because no boundary exists.
Two autonomous agents entered a recursive loop. They ran for 11 days, accumulating $47,000 in API costs before anyone noticed. The observability infrastructure existed. Nobody was watching the dashboard. There was no automated enforcement to stop the loop or cap the cost. [Source: Tech Startups — $47,000 AI Agent Failure]
What the kernel provides: Loop detection, cost bounds, step limits, and timeout enforcement. The Prevention Stack defaults (3 iterations, $10, 100 steps) mean agents are bounded from the first execution.
4.5 Governed Visibility
The failure it prevents: Black-box agents where no one (not the developer, not the team lead, not the compliance officer) can understand why the agent did what it did.
Observability alone is not enough. Governed visibility means structured reasoning replay (not just traces), decision audit trails (not just logs), and shared understanding across technical and non-technical stakeholders. An engineer sees the reasoning chain. A CX team lead sees the business rule that triggered. A compliance officer sees the policy that was enforced.
What the kernel provides: Reasoning replay, decision audit trails, and multi-stakeholder visibility. Everyone who needs to understand the agent's behavior can, at the level of detail they need.
5. The Five Dimensions
The capabilities are the enforcement side. The Agent Reliability Index (ARI) is the measurement side — how you know whether the enforcement is actually working. You cannot improve what you cannot measure. The kernel introduces five dimensions, one per capability:

| Dimension | Abbreviation | What It Measures |
|---|---|---|
| Context Integrity | CII | Is the agent operating on accurate, fresh, complete information? |
| Memory Consistency | MCS | Are memories grounded in facts? Are contradictions detected and resolved? |
| Action Governance | AGS | Are policies enforced? Are actions within defined boundaries? |
| Execution Determinism | EDS | Are costs predictable? Are runs bounded? Is execution reproducible? |
| Observability Coverage | OCS | Can every decision be understood, audited, and replayed? |
Each dimension scores 0-100%. An agent with CII at 85% and AGS at 72% tells a specific story: context handling is strong, but action governance needs investment. This is actionable. "The agent is unreliable" is not.
Why five dimensions, not one score? A single reliability number hides the signal. An agent that scores 80% overall might have CII at 95% and AGS at 40%, meaning context is excellent but action governance is dangerously weak. The five dimensions force specificity. They enable targeted improvement. And they create a common language for discussing agent reliability across teams, vendors, and organizations.
The analogy: traditional infrastructure has SLIs (Service Level Indicators) and SLOs (Service Level Objectives). You do not measure uptime with a single number; you measure latency, error rate, throughput, and availability independently. The ARI framework brings this discipline to agents.
The five dimensions map directly to the five capabilities:
| Capability | Dimension | What Improvement Looks Like |
|---|---|---|
| Context Intelligence | CII | Fewer stale-context incidents, higher freshness scores |
| Memory Integrity | MCS | Fewer confabulated memories, zero contradiction tolerance |
| Action Governance | AGS | Policy violations drop to near-zero, all exceptions logged |
| Execution Reliability | EDS | Cost variance narrows, no runaway executions |
| Governed Visibility | OCS | Every decision auditable, replay coverage at 100% |
This is the measurement layer that makes the Agent Kernel self-improving. Low CII scores trigger investigations into context pipeline quality. Low AGS scores trigger policy reviews. The kernel does not just enforce. It measures, and what gets measured gets managed.
6. Why This Matters Now
We see three forces converging in 2026 that make this the kernel moment for AI agents.
Force 1: the adoption curve has crossed the governance threshold. 40% of enterprise applications will feature AI agents by the end of 2026. [Source: Gartner, August 2025] This is not experimentation anymore. Agents are being deployed in customer service, financial operations, healthcare triage, and legal research. The stakes are real: real money, real customers, real regulatory exposure. Every enterprise deploying agents without runtime governance is accumulating risk.
Force 2: MCP created the protocol layer, without the governance layer. The Model Context Protocol, open-sourced by Anthropic in November 2024, has grown into an industry standard. It is backed by OpenAI, Google, Microsoft, and the Linux Foundation, with over 2,000 MCP servers in the public registry. [Source: MCP Blog — First Anniversary] MCP solved the connectivity problem: agents can now access any tool, from local Redis databases to GitHub repositories, through a standard protocol. But MCP has no native governance. Tools have no permission boundaries. Actions have no cost limits. Sessions have no execution bounds. MCP created the agent equivalent of networking without firewalls. The governance layer is the obvious next step, and it does not exist yet.
Force 3: the failure data is undeniable. 95% of agent projects fail to reach production. 40% will be canceled by 2027 specifically due to inadequate risk controls. Tool calling (the mechanism by which agents interact with systems) fails 3-15% of the time in production, even in well-engineered systems. [Source: Composio — Why AI Agent Pilots Fail] These are not edge cases. These are systemic failures caused by a missing infrastructure layer.
The pattern from IAM, Kubernetes, and Terraform is clear: the governance layer emerges when the failure rate at scale becomes intolerable. That moment is now.
What Comes Next
The Agent Kernel is not a product you install and forget. It is a foundational layer that changes how teams build, deploy, and operate AI agents.
For teams evaluating their agent infrastructure, three questions matter:
- Do you have runtime enforcement? Not just observation. Not just input/output validation. Can your infrastructure stop an agent mid-execution when it violates a boundary? If the answer is no, you have an observability gap, not a reliability solution.
- Are your defaults specific? "Configurable limits" is not a safety posture. Specific defaults (3 iterations, $10, 100 steps) mean agents are safe out of the box. Teams that cannot articulate their defaults do not have governance. They have intentions.
- Can you measure reliability across dimensions? A single "health" score hides failure modes. Five dimensions (CII, MCS, AGS, EDS, OCS) force the specificity that drives improvement. If you cannot break your agent's reliability into measurable components, you cannot systematically improve it.
The technology works. What is missing is the infrastructure layer that makes it governable. That is the layer we are building.
It is the Agent Kernel.
Getting Started: Quick Start Guide
Install the Clyro SDK:
pip install clyro
Wrap your agent with governance:
import clyro
from clyro import ClyroConfig, ExecutionControls
wrapped = clyro.wrap(
your_agent,
config=ClyroConfig(
agent_name="support-triage-agent",
controls=ExecutionControls(
max_steps=100, # Cap actions per run
max_cost_usd=10.0, # Hard cost ceiling
# ... loop detection + policy enforcement (full block below)
),
),
)
View full wrap + invoke example
import clyro
from clyro import ClyroConfig, ExecutionControls
wrapped = clyro.wrap(
your_agent,
config=ClyroConfig(
agent_name="support-triage-agent",
controls=ExecutionControls(
max_steps=100, # Cap actions per run
max_cost_usd=10.0, # Hard cost ceiling
enable_loop_detection=True, # Halt on repeated patterns
loop_detection_threshold=3,
enable_policy_enforcement=True,
),
),
)
result = wrapped.invoke({"messages": [{"role": "user", "content": "..."}]})
The SDK defaults mean an agent is bounded from the first execution: no $47K loops, no 260-McNugget orders, no runaway cost.
Define business logic as a YAML policy:
id: quantity_limit
name: "Order Quantity Limit"
description: "Require approval for orders over 50 units"
category: action_governance
rules:
version: "1.0"
default_action: allow
rules:
- id: rule-qty-50
name: qty_over_50
condition:
field: order.quantity
# ... operator + value + action + message (full policy below)
View full policy YAML
id: quantity_limit
name: "Order Quantity Limit"
description: "Require approval for orders over 50 units"
category: action_governance
rules:
version: "1.0"
default_action: allow
rules:
- id: rule-qty-50
name: qty_over_50
condition:
field: order.quantity
operator: max_value
value: 50
action: require_approval
message: "Order exceeds 50 units. Approval required."
Policies use three actions (block, allow, require_approval) and load from ~/.clyro/sdk/policies.yaml. The Runtime Layer enforces them on every tool call.
Next steps: The Prevention Stack walks through the four Runtime Layer components in depth. MCP Security covers governance for MCP-connected agents specifically.
Frequently Asked Questions
What is an Agent Kernel?
The Agent Kernel is the runtime governance infrastructure for AI agents — the missing layer that sits between the model and the outside world and enforces what an agent is allowed to do, not just records what it did. It provides five capabilities: context validation (grounds answers in current sources), memory integrity (prevents confabulation and memory poisoning), action governance (enforces policies before side effects), execution bounds (caps cost, steps, and loops), and governed visibility (reasoning replay + audit trails).
Each capability targets a documented failure class — Air Canada's stale-context lawsuit, the McDonald's 260-McNugget drive-thru incident, the $47K API-cost runaway — and replaces reactive monitoring with pre-event enforcement. It plays the role IAM played for cloud, Kubernetes for containers, and Terraform for infrastructure: the unified governance layer that makes a production technology safe to scale. Without it, agent deployments rely on prompt-level instructions and eyeballs-on-dashboards, neither of which halt a misbehaving agent in flight.
Why do AI agents need a kernel if observability already exists?
Observability is record-keeping. It tells you an agent ran for 11 days, invoked the same API 4,800 times, and spent $47,000 — after the fact. It does not stop the loop. The Agent Kernel enforces cost ceilings (e.g., $10/execution), loop detection (halt after 3 repeated sub-task iterations), step limits (cap at 100 actions), and business-logic policy (refund thresholds, action allowlists) at runtime, before damage clears. Dashboards require someone watching at 3 a.m. on a Sunday; enforcement does not.
The distinction maps to control planes in other infrastructure: Kubernetes emits metrics and enforces pod limits; IAM emits audit logs and blocks unauthorized API calls. Agent deployments today have the observability half — Langfuse, Arize, LangSmith — and the enforcement half almost entirely missing. Both are necessary and they're not substitutes. The Agent Kernel is the enforcement half, and it prevents incidents observability only documents. The $47K Loop, the McDonald's 260-McNugget order, Air Canada's stale-policy lawsuit — all were traced, none were halted.
How is the Agent Kernel different from MCP (Model Context Protocol)?
MCP and the Agent Kernel sit at different layers and solve different problems — they are complementary, not overlapping.
MCP solves connectivity: agents access any tool through a standard protocol. Over 2,000 MCP servers are in the public registry, and the protocol is backed by Anthropic, OpenAI, Google, Microsoft, and the Linux Foundation. What MCP explicitly does not address: permission boundaries (which agent can call which tool with which arguments), cost and rate limits (how many calls, at what spend ceiling), execution bounds (how many steps, what loop-detection threshold), or business-logic policy (refund thresholds, action allowlists, approval workflows). The MCP specification treats those as out-of-scope application concerns.
The Agent Kernel is that missing governance layer. The clean analogy: MCP is TCP/IP — the protocol that lets everything talk to everything — and the kernel is the firewall + IAM + rate limiter that determines what any given agent is actually allowed to do. Production agent deployments need both; MCP without a kernel is a standards-compliant way to have expensive incidents.
What are the five capabilities of the Agent Kernel?
Five, each targeting a distinct class of production failure and each replacing a specific "monitor it after it happens" workflow with runtime enforcement:
- Context Intelligence — validates the freshness, source, and relevance of everything going into the prompt; prevents Air Canada-style stale-policy failures where the agent confidently cites superseded content.
- Memory Integrity — grounds long-term memory in verifiable facts with provenance and trust tiers; prevents confabulation poisoning the vector store across sessions (the "Goldfish Problem").
- Action Governance — enforces declarative policies (YAML-described allow/block/require-approval rules) and approval workflows before side effects clear; would have blocked the 260-McNugget order and the $600 unauthorized refund.
- Execution Reliability — loop detection (halt after 3 repeated sub-task iterations), cost bounds ($10/execution), step limits (100 actions), timeout policies; stops $47K-style runaways.
- Governed Visibility — reasoning replay (not just spans) and audit trails queryable across engineering, legal, and compliance stakeholders.
Five is not arbitrary: every documented production incident in the 699-incident agent-failure dataset maps cleanly to one of the five — fewer capabilities leaves a class uncovered.
How does the Agent Kernel relate to the Agent Reliability Index (ARI)?
The Agent Kernel and the Agent Reliability Index (ARI) are two sides of the same framework. The five kernel capabilities map 1:1 to five ARI dimensions: Context Integrity (CII), Memory Consistency (MCS), Action Governance (AGS), Execution Determinism (EDS), and Observability Coverage (OCS). Each is scored 0–100% against documented probes — e.g., CII scores how many agent responses cite a verifiable current source; AGS scores how many policy-violating actions were blocked rather than alerted.
The capabilities are what the kernel does at runtime; ARI is how you measure whether it is actually working in production. A single "reliability" number collapses signal — you cannot tell whether the agent failed because its memory was corrupted or because its action governance had a gap. Five dimensions preserve that signal and make improvement targetable: a low CII score sends you to tighten context freshness validation; a low AGS score sends you to expand the policy coverage. For teams already running the kernel, ARI is the weekly scoreboard that tells you which capability needs the next engineering investment.
Should I build my own Agent Kernel or use a platform?
Honest math: each of the five capabilities represents months of dedicated engineering. A production-grade policy DSL with allow/block/require-approval semantics and hot-reload is ~3 months. Memory consistency checks with provenance tracking and drift detection is ~4 months. Reasoning replay and Think→Act→Observe tracing infrastructure is ~3 months. Cross-agent learning (using one agent's failures to update another's defaults) is ~2 months. Governed visibility with role-based views and audit export is ~2 months. That is 14+ engineer-months before one line of business logic gets written — and most of that work is undifferentiated infrastructure that no end-user ever sees.
Teams that try typically ship two or three capabilities and declare victory, then leave the remaining three on a roadmap that never gets prioritized. A platform Agent Kernel delivers all five on day one and adds an Intelligence Layer on top — adaptive defaults learned across customers, industry-specific policy templates, drift detection benchmarked against peer deployments — that only compounds with scale. Build in-house if your governance is a competitive moat; use a platform if it is table stakes.
When will the Agent Kernel category mature?
Governance-layer patterns consistently emerge when failure rates at scale become intolerable — and every piece of current data says the intolerance point for agents is now, not in 2027.
Historical precedent: AWS launched in 2006; IAM shipped as a standalone service in 2011 after five years of increasingly expensive permission mistakes. Docker shipped in 2013; Kubernetes reached 1.0 in 2015 after container fleets grew past what ad-hoc orchestration could handle. In both cases the "why now?" was the same: deployments scaled to a point where the absence of governance generated more engineering cost than the cost of building governance.
AI agents are at that inflection. Gartner projects 40% of enterprise applications will feature task-specific agents by end of 2026, up from under 5% in 2025. MIT's August 2025 study found 95% of generative-AI pilots fail to reach production. Gartner separately predicts 40%+ of agentic projects will be cancelled by end of 2027 — a direct signal that ungoverned deployments do not survive. Expect the Agent Kernel category to consolidate across 2026–2027, with the naming pattern following IAM / K8s / Terraform: a platform-level primitive that the next wave of agent work simply assumes.
Get Started
Install the SDK and add runtime governance to your agents in under a minute.
pip install clyro
Free tier: 10 agents, 100K traces/month, no credit card required.
Works with LangGraph, CrewAI, Claude Agent SDK, Anthropic SDK, and any Python callable.
Sign Up Free → | GitHub → | Docs →
Related Resources
- The 5 Agent Failure Modes — signals that show when each mode is failing and how to stop it from happening.
- The Prevention Stack: Beyond Observability — how runtime governance works in practice.
- MCP Security: Governing Claude's Tools — what happens when the protocol layer exists without the governance layer.
Sources
[1] AWS — Happy 10th Birthday IAM — History of AWS IAM launch and growth
[2] Kubernetes Blog — 10 Years of Kubernetes — Origin and evolution of Kubernetes
[3] HashiCorp — The Story of Terraform — Terraform founding story and growth
[4] DemandSage — AI Agents Market Size — AI agent market size data ($7.63B in 2025)
[5] Gartner Press Release, August 2025 — 40% of enterprise apps to feature AI agents by 2026
[6] MIT/Fortune, August 2025 — 95% of enterprise AI agent projects fail to reach production
[7] Gartner Press Release, June 2025 — 40% of agentic AI projects to be canceled by 2027
[8] ABA — Moffatt v. Air Canada — Air Canada chatbot bereavement policy incident
[9] Tech Startups — $47,000 AI Agent Failure — $47K recursive loop incident
[10] MCP Blog — First Anniversary — MCP protocol growth and adoption data
[11] Composio — Why AI Agent Pilots Fail — Tool calling failure rates in production