
From 'AI does the work of 700 agents' to a hybrid Uber-style workforce — the full Klarna arc, diagnosed as an infrastructure failure, with a Prevention Stack mapping for teams scaling AI today.
1. The Triumph — Klarna AI Launches (Feb 2024)
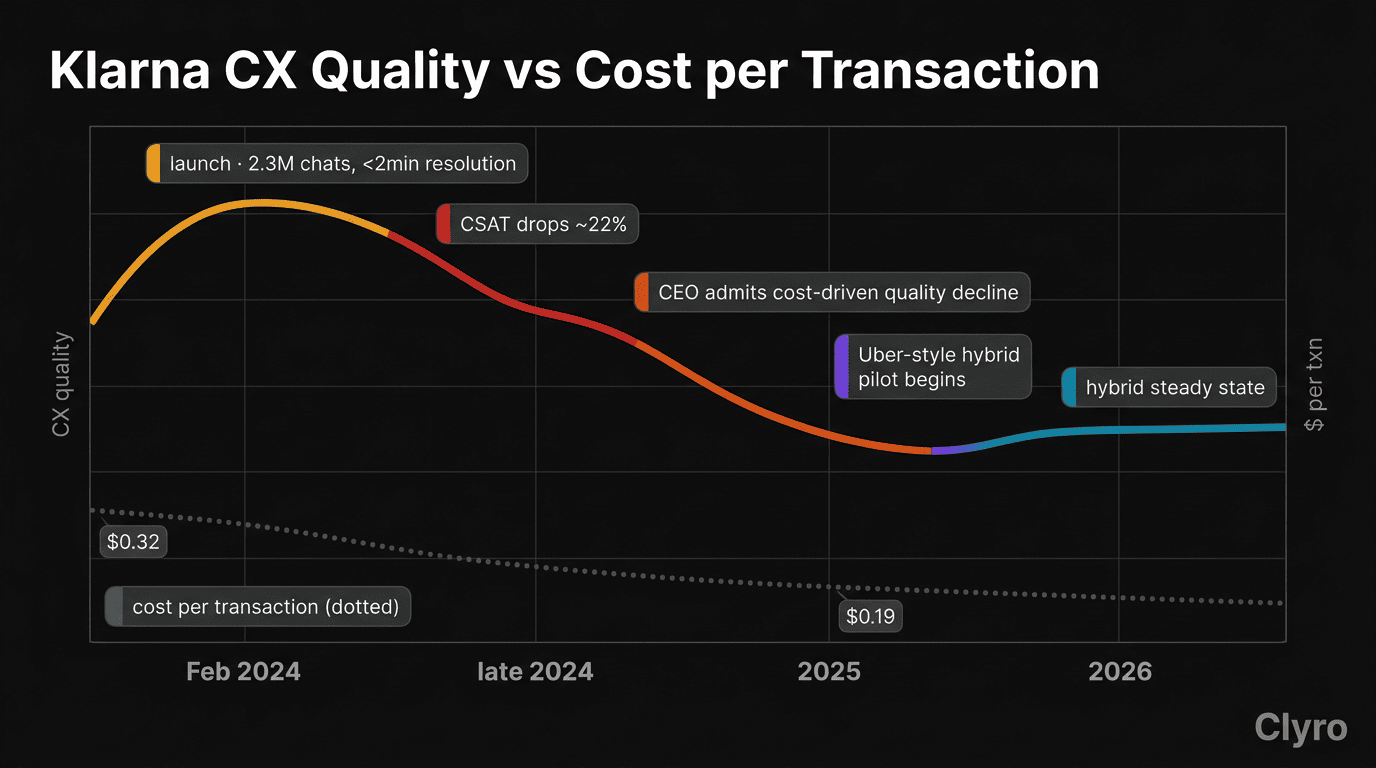
February 2024. Klarna's press release became the most cited proof point in the AI-replaces-jobs narrative: its OpenAI-powered assistant handled 2.3M customer service conversations in month one — two-thirds of all Klarna service chats — "doing the equivalent work of 700 full-time agents." [Source: Klarna PR, Feb 2024]
Numbers were striking. Resolution time dropped from 11 minutes to under 2. Repeat inquiries fell 25%. 24/7 across 23 markets and 35 languages. Klarna estimated a $40M profit improvement for 2024. [Source: OpenAI case study]
CEO Sebastian Siemiatkowski leaned in — called Sam Altman and asked to be OpenAI's "favorite guinea pig." Klarna froze hiring. Headcount dropped from 5,527 at end of 2022 to 3,422 by December 2024 — a 38% reduction. Siemiatkowski framed it as natural attrition ("We shrink naturally 15–20% by people just leaving"), but the message was unmistakable. [Source: CNBC, May 2025]
The industry took the cue. Klarna became the standard slide in every "AI is replacing customer service" deck for the next 12 months. 700 agents, replaced.
2. The Decline (late 2024 – 2025)
Then the story changed. By early 2025, Siemiatkowski told Bloomberg the AI-focused strategy "wasn't the right path." His later CX Dive post-mortem: "Cost unfortunately seems to have been a too predominant evaluation factor. What you end up having is lower quality." [Source: CX Dive]
"Lower quality" understates it. Customer satisfaction dropped ~22% after rollout. [Source: Strategic Marketing Tribe; FinTech Weekly] Leadership metrics (cost per transaction, AI deflection rate) looked healthy. Customer metrics (resolution quality, escalation success, trust) quietly degraded.
Cost per transaction fell 40% — from $0.32 in Q1 2023 to $0.19 in Q1 2025. [Source: CX Dive] Savings were real. They came at the expense of customer trust, which is harder to measure and slower to surface.
By Q1 2025 the rehiring decision was effectively made. Arc from "AI does the work of 700 agents" to "we need humans again": ~14 months.
3. The Pivot (2026)
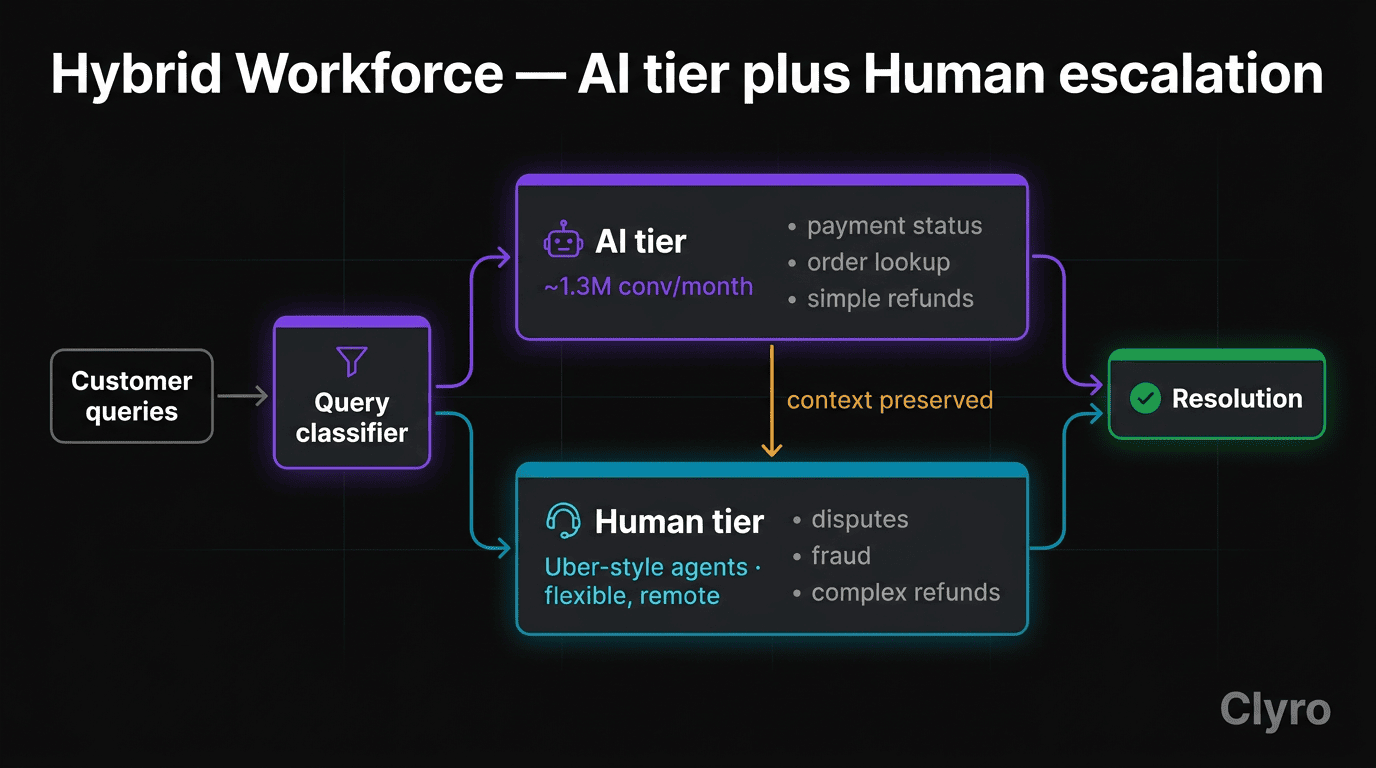
Spring 2025. Klarna piloted what Siemiatkowski called an "Uber-style" customer service model — remote workers with flexible schedules, paid competitively, recruited from students, rural residents, and existing Klarna users. Explicitly hybrid: AI handles two-thirds (~1.3M chats/month mid-2025), humans handle disputes, refunds, fraud, anything requiring discretion or empathy. [Source: Entrepreneur, 2025; PromptLayer]
The "Klarna fired 700 people" headline missed this part. Klarna isn't abandoning AI — the 2026 architecture keeps the AI tier (savings real, speed real, most simple queries genuinely don't need a human). Added: a second tier of humans picking up cases the AI can't, with context-preserving handoffs.
Post-IPO context matters. Klarna filed in March 2025, paused during market turbulence, and completed in September 2025 at a $15B+ valuation. [Source: CNBC, Mar 2025] A public company can't quietly walk back its AI story; Siemiatkowski's "lower quality" admission was on-record because the alternative (insisting AI replaced 700 people while rehiring) wasn't viable.
2026 reality: AI deflection at scale + a human escalation tier the company is publicly committed to. The model that should have shipped in early 2024, not the all-AI-everything that actually did.
4. Diagnosis: Infrastructure Failure, Not AI Failure
Siemiatkowski's admission (§2) names the mechanism: cost-driven scaling produced lower quality. It doesn't name how. The decline clustered around three predictable patterns, each an infrastructure gap — not a model gap.
Generic, repetitive responses. The AI handled simple queries fine (payment status, order details). Anything requiring context-dependent reasoning got canned replies — disputed-charge queries and routine-refund queries got functionally identical responses. [Source: Voiceflow]
Failed handoffs. When AI couldn't resolve, handoff was lossy. Customers restarted their problem from scratch; context didn't pass forward. [Source: Twig.so]
Over-automation of complex cases. Klarna routed disputes, fraud, and multi-step financial queries through AI — exactly where capable LLMs are least reliable. Fraud-transaction customers got trapped in unproductive loops. [Source: LaSoft]
All three are infrastructure problems, not model problems. Generic responses lack runtime grounding; failed handoffs lack a context preservation layer; over-automation lacks a classification layer routing by complexity.
Forrester's Christina McAllister named the same root cause: Klarna "underestimated the complexity of their customer service operations" with an "overzealous pursuit of cost reduction." [Source: Silicon Republic]
5. The Generalizable Pattern
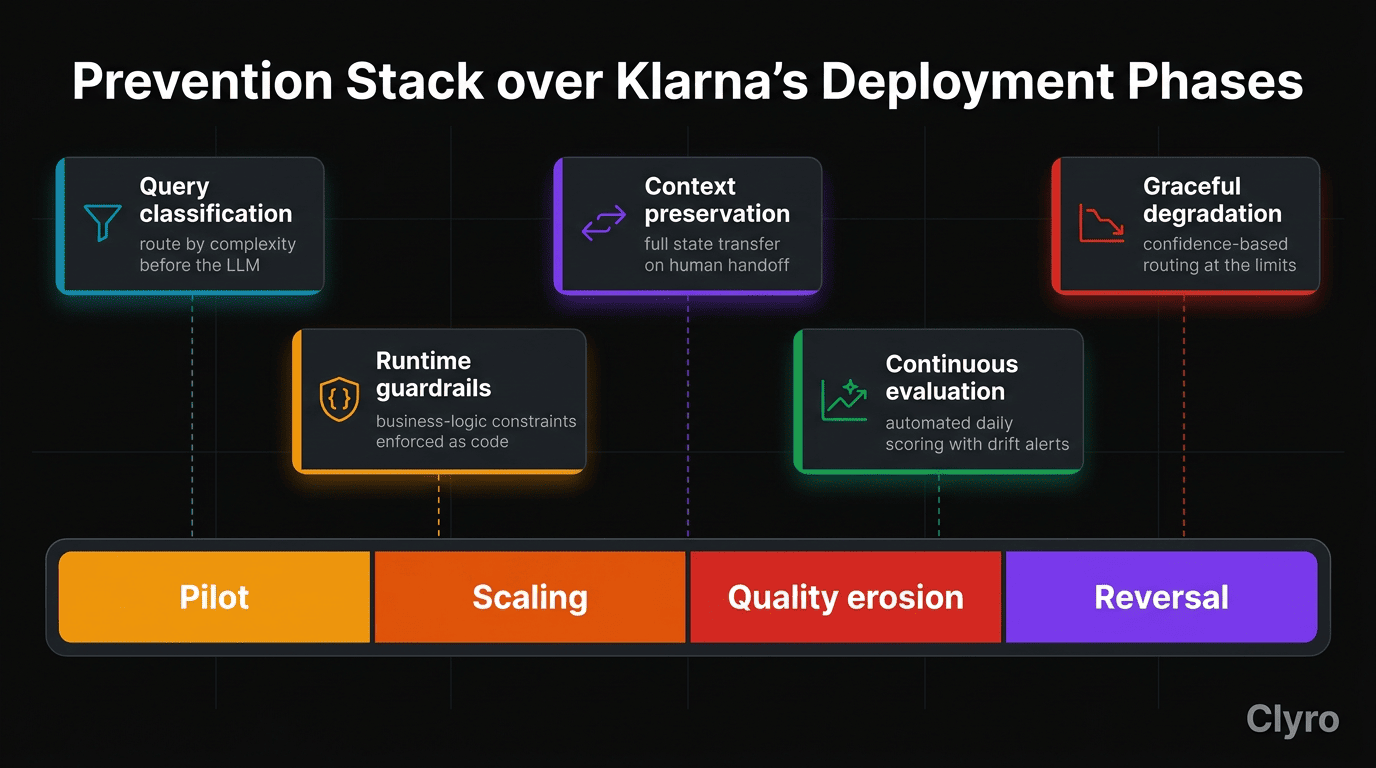
Klarna's arc follows a repeating pattern:
- Phase 1: Pilot. AI handles narrow queries under controlled conditions. Metrics look strong.
- Phase 2: Scaling. Company routes more traffic + edge cases through AI; headcount drops. System now handles scenarios never validated.
- Phase 3: Quality erosion. Complaints rise; savings are real and visible, so decline gets rationalized — "still tuning," "users will adjust."
- Phase 4: Reversal. Gap becomes impossible to ignore. Company announces a "hybrid approach."
McDonald's followed the pattern. IBM-built AI drive-thru at 100+ U.S. locations hit ~85% order accuracy. At McDonald's global volume of 70 million daily customers, a 15% error rate would translate to 10M+ wrong orders per day if rolled out everywhere — the kind of projection that stops a scaling plan cold. The partnership ended June 2024 after 3 years of testing, with viral TikTok of the system adding 260 McNuggets to one order. [Source: CNBC, Jun 2024; Museum of Failure]
Dukaan, an Indian e-commerce platform, compressed the arc into months. CEO Suumit Shah announced replacing 90% of support staff with AI in mid-2023; the backlash was immediate, reputation damage lasting. [Source: Fortune, Jul 2023]
Broader data confirms systemic: a 2025 MIT study found 95% of enterprise generative AI pilots deliver zero measurable return. S&P Global reports the share of companies abandoning most AI initiatives jumped from 17% to 42% year-over-year. [Source: Fortune/MIT, Aug 2025; CIO Dive]
The answer isn't that AI isn't ready. It's that AI is being deployed without the infrastructure to keep it reliable at scale. Pilots work because they're monitored, bounded, and controlled; production at scale is none of those. The gap between "works in pilot" and "reliable at scale" is an infrastructure gap, not a model gap.
6. The Missing Layer — 5 Dimensions of Reliable AI at Scale
The typical agent stack is an LLM API + prompting layer + RAG pipeline + thin app wrapper. That's deploying a web app with no load balancer, no circuit breakers, no health checks. Works on your laptop; fails in production.
Reliable AI at scale requires at least five infrastructure dimensions. Observability is one — necessary, not sufficient:
Dimension 1: Query classification and routing
Not every query should go to AI. Disputes, fraud, high-value financial issues require human judgment. A classification layer routing by complexity, risk, and topic — applied before the query hits the LLM — prevents the AI from attempting tasks it's structurally unsuited for. Klarna routed everything through AI; that's why fraud cases ended up in loops.
Dimension 2: Runtime guardrails
Model output needs business-logic checks before reaching the customer. Refund limits, policy accuracy, and regulatory compliance can't be prompt instructions. Prompts are suggestions; guardrails are constraints enforced at runtime, hard boundaries the model can't override.
This is the Prevention Stack pattern: loop detection (3 iterations), cost bounds ($10/execution), step limits (100 actions), business-logic guardrails (domain rules in code). For Klarna, a refund-approval guardrail as a Clyro policy:
# Refund approval threshold — enforced at runtime, not in the prompt
id: klarna_refund_approval
name: "Refund Approval — High-Value Threshold"
category: business_logic
rules:
default_action: allow
rules:
- id: rule-refund-require-approval
condition: {field: refund_amount_usd, operator: requires_approval, value: 100}
action: require_approval
- id: rule-refund-block-high-value
condition: {field: refund_amount_usd, operator: greater_than, value: 500}
action: block
# ... full policy with descriptions + messages in collapsed block below
View full YAML policy
# Refund approval threshold — enforced at runtime, not in the prompt
id: klarna_refund_approval
name: "Refund Approval — High-Value Threshold"
description: "Require human approval for refunds above $100. Block AI-driven refunds entirely above $500."
category: business_logic
rules:
version: "1.0"
default_action: allow
rules:
- id: rule-refund-require-approval
name: refund_requires_approval
description: "Require human approval for refunds between $100 and $500"
condition:
field: refund_amount_usd
operator: requires_approval
value: 100
action: require_approval
message: "Refund of ${{refund_amount_usd}} requires manager approval (threshold: $100)"
- id: rule-refund-block-high-value
name: refund_block_high_value
description: "Block AI-initiated refunds above $500 outright — must escalate to human"
condition:
field: refund_amount_usd
operator: greater_than
value: 500
action: block
message: "Refund of ${{refund_amount_usd}} exceeds AI authority limit ($500). Escalating to human agent."
A YAML rule like this is the difference between an AI that might respect refund limits because the prompt asked nicely, and one that cannot exceed them because the runtime won't let it. Klarna had the prompt-level version; the runtime enforcement layer was missing.
Dimension 3: Context preservation
When AI can't resolve, the human handoff must carry full context — problem statement, prior resolution attempts, escalation reason, account data. Klarna's handoff was lossy; customers repeated themselves. That single gap likely accounted for a disproportionate share of the satisfaction drop.
Dimension 4: Continuous quality evaluation
A single launch CSAT score doesn't tell you how the system performs six months later. Quality must be measured continuously — automated scoring on a sample of daily interactions, with drift alerts. Klarna's initial metrics showed CSAT "on par with human agents"; the decline was gradual. This is Failure Mode 5: Silent Degradation — quality erodes slowly enough that no single interaction triggers an alert, but the cumulative effect destroys trust.
Dimension 5: Graceful degradation
When AI hits its limits, the system should degrade gracefully: low confidence → human; upstream model version change → regression tests before production. Controlled and predictable, not "customers posting complaint threads on social media."
None of these five is about LLM capability. The model isn't the bottleneck — the infrastructure between model and customer is.
7. The Lesson — Infrastructure Beats Headcount
Siemiatkowski's post-reversal framing: "From a brand perspective, a company perspective, I just think it's so critical that you are clear to your customer that there will always be a human if you want." [Source: Entrepreneur, 2025] Right instinct, wrong solution.
The lesson isn't "hire more humans" — that's expensive and unscalable. It's: build the infrastructure layer that makes AI reliable enough that you don't have to choose between cost and quality. Klarna framed AI vs. humans (700 replaced, some fraction rehired). The actual answer is neither — AI with runtime governance, the infrastructure that prevents the reversal.
The five dimensions mapped against Klarna's deployment:
| Dimension | What Klarna Had | What Was Needed |
|---|---|---|
| Query classification | Everything routed to AI | Complexity-based routing |
| Runtime guardrails | Prompt-level instructions | Enforced business logic constraints |
| Context preservation | Lossy handoffs | Full context transfer on escalation |
| Continuous evaluation | Point-in-time CSAT | Automated daily scoring with drift alerts |
| Graceful degradation | Binary AI/human | Confidence-based dynamic routing |
Every row in the "What Was Needed" column is infrastructure. Not headcount. Not a better model. Not more training data.
What to implement before scaling
- Query classification — route by complexity before queries hit the LLM
- Runtime guardrails as code — business-logic constraints enforced at execution, not in prompts
- Continuous quality evaluation — automated daily scoring with drift alerts, not point-in-time CSAT
- Graceful degradation paths — confidence-based routing designed before you need it
This is the Agent Kernel pattern — runtime governance between model and environment that enforces constraints, preserves context, evaluates quality, and degrades gracefully at the limits.
The Klarna reversal isn't AI failing. It's a company deploying AI without the reliability infrastructure any production system requires. The model worked. The infrastructure around it didn't exist. Teams deploying at scale will face the same decision point. Those who build the infrastructure first won't need the reversal.
Klarna's story is one instance of a broader pattern. For the taxonomy of how agents fail in production, see The 5 Agent Failure Modes. For the architecture that prevents these failures, see The Prevention Stack: Beyond Observability.
Get Started
Install the SDK and add runtime governance to your agents in under a minute.
pip install clyro
Free tier: 10 agents, 100K traces/month, no credit card required.
Works with LangGraph, CrewAI, Claude Agent SDK, Anthropic SDK, and any Python callable.
Sign Up Free → | GitHub → | Docs →
FAQ
Did Klarna actually fire 700 people because of AI?
Not directly. Klarna froze hiring; attrition dropped headcount from 5,527 (end 2022) to 3,422 (Dec 2024) — 38%. The "700 agents" framing is from Klarna's Feb 2024 PR claiming the AI did "the equivalent work of 700 full-time agents" in month one. Productivity equivalence, not layoffs — people weren't fired, they weren't backfilled. By 2026, Klarna is rehiring under an "Uber-style" flexible model for cases AI can't handle.
Is Klarna abandoning AI customer service?
No. 2026 architecture keeps AI as the front line — still two-thirds of conversations (~1.3M chats/month). Klarna added a second tier: humans picking up cases AI can't, with context-preserving handoffs. Not an "AI is too hard" retreat — recognition that scale without reliability infrastructure produces quality erosion, and some cases (disputes, fraud, high-value refunds) need human discretion. The savings are still real; what changed is the deployment architecture around it.
What specifically failed in Klarna's deployment — was it the model?
The model worked. Failures were infrastructure gaps: generic responses (no runtime grounding), failed handoffs (no context preservation), over-automation (no classification layer — fraud routed through AI, where LLMs are least reliable). CSAT dropped ~22%. Siemiatkowski: "Cost...a too predominant evaluation factor...lower quality." Forrester's McAllister: "overzealous pursuit of cost reduction."
What is the "Uber-style" workforce model Klarna is now testing?
Remote workers with flexible schedules, paid competitively, recruited from students, rural residents, and existing Klarna users. Pilot started spring 2025. "Uber-style" refers to the on-demand, app-dispatched pattern — not Uber's employment classification. Explicitly hybrid: AI handles routine high-volume queries; humans handle anything requiring discretion (disputes, fraud, complex refunds). Context-preserving handoffs between tiers. The hybrid that should have shipped in early 2024.
Could observability tools like LangSmith or Arize have caught this earlier?
Partially. Observability would have shown response times fast, token counts expected, AI responding — all healthy. What it wouldn't show is the business-outcome degradation: generic responses to nuanced queries, lossy handoffs, context-free escalations. LLM-as-judge evals get closer but need calibration most deployments lack. Fundamentally observability records; it doesn't intervene. See Why Observability Isn't Enough for AI Agents for the full argument.
What would a properly governed Klarna-style deployment look like?
Five infrastructure dimensions between LLM and customer: (1) Query classification routing disputes/fraud/high-value to humans before AI; (2) Runtime guardrails as code (see §6 YAML); (3) Context preservation on handoff; (4) Continuous evaluation with drift alerts; (5) Graceful degradation via confidence-based routing. The Agent Kernel pattern.
Is this pattern likely to repeat at other AI-at-scale companies?
Already has. Three documented arcs: Klarna (14 months, partial reversal), McDonald's (3 years IBM drive-thru, 100 locations, ended Jun 2024), Dukaan (90% layoffs mid-2023, backlash). Systemic data: MIT 2025 — 95% of enterprise generative AI pilots deliver zero measurable return; S&P Global — abandonment jumped 17%→42% YoY; Gartner — 40%+ of agentic projects canceled by end 2027. Companies that avoid this build infrastructure first.
Related Resources
- The 5 Agent Failure Modes: Why AI Agents Fail in Production — The taxonomy of production agent failures, including Silent Degradation
- The $47K Loop: A Complete Forensic Analysis — What happens when agents lack execution bounds
- 260 McNuggets: When AI Orders for You — McDonald's AI failure and the case for business logic guardrails
- The Prevention Stack: Beyond Observability — The four-component framework for runtime agent governance
Sources
[1] Klarna Press Release — AI Assistant Handles Two-Thirds of Customer Service Chats, February 2024 — Klarna's initial AI deployment announcement. https://www.klarna.com/international/press/klarna-ai-assistant-handles-two-thirds-of-customer-service-chats-in-its-first-month/
[2] OpenAI Case Study — Klarna — Performance metrics from Klarna's AI assistant rollout. https://openai.com/index/klarna/
[3] CNBC — Klarna CEO Says AI Helped Company Shrink Workforce by 40%, May 2025 — Headcount reduction details. https://www.cnbc.com/2025/05/14/klarna-ceo-says-ai-helped-company-shrink-workforce-by-40percent.html
[4] Entrepreneur — Klarna CEO Reverses Course by Hiring More Humans, 2025 — Klarna's reversal and rehiring announcement. https://www.entrepreneur.com/business-news/klarna-ceo-reverses-course-by-hiring-more-humans-not-ai/491396
[5] CNBC — Klarna CEO Faces Biggest Test Yet: IPO, March 2025 — Klarna IPO context and AI strategy shift. https://www.cnbc.com/2025/03/31/klarna-ceo-sebastian-siemiatkowski-faces-biggest-test-yet-ipo.html
[6] CX Dive — Klarna Reinvests in Human Talent for Customer Service, 2025 — CEO quote on cost vs. quality tradeoff. https://www.customerexperiencedive.com/news/klarna-reinvests-human-talent-customer-service-AI-chatbot/747586/
[7] Strategic Marketing Tribe — Klarna AI Backlash, 2025 — Customer satisfaction decline data. https://strategicmarketingtribe.com/marketing-news/b/klarna-ai-backlash-human-support-trend-2025
[8] Voiceflow — How Klarna's Agent Falls Short — Technical analysis of Klarna AI limitations. https://www.voiceflow.com/pathways/behind-the-hype-how-klarnas-customer-support-agent-falls-short
[9] Twig.so — What Klarna Got Wrong About AI in Customer Support — Handoff failure analysis. https://www.twig.so/blog/what-klarna-got-wrong-about-ai-in-customer-support--and-how-they-fixed-it
[10] LaSoft — Klarna Walks Back AI Overhaul — Over-automation of complex cases. https://lasoft.org/blog/klarna-walks-back-ai-overhaul-rehires-staff-after-customer-service-backlash/
[11] Silicon Republic — Klarna AI Hiring Humans, Forrester Analysis, 2025 — Forrester analyst assessment. https://www.siliconrepublic.com/machines/klarna-ai-hiring-humans-forrester
[12] CX Dive — Klarna AI Slash Customer Service Costs, 2025 — Cost per transaction data. https://www.customerexperiencedive.com/news/klarna-ai-slash-customer-service-costs/748647/
[13] CNBC — McDonald's Ends AI Drive-Thru Test, June 2024 — McDonald's AI ordering failure. https://www.cnbc.com/2024/06/17/mcdonalds-to-end-ibm-ai-drive-thru-test.html
[14] Fortune — Dukaan CEO Slammed for Replacing 90% of Support Staff, July 2023 — Dukaan AI replacement backlash. https://fortune.com/2023/07/12/dukaan-ceo-slammed-replacing-90-percent-company-support-staff-with-ai-chatbot-bragging-twitter-backlash/
[15] Fortune — MIT Report: 95% of Generative AI Pilots Failing, August 2025 — Enterprise AI pilot failure rates. https://fortune.com/2025/08/18/mit-report-95-percent-generative-ai-pilots-at-companies-failing-cfo/
[16] CIO Dive — AI Project Failure Rates, S&P Global — AI project abandonment statistics. https://www.ciodive.com/news/AI-project-fail-data-SPGlobal/742590/