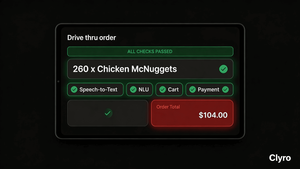
260 McNuggets on one order and every trace showed success. A forensic look at AI agent business logic failure and how to stop it.
How an AI drive-thru system turned a simple order into 260 McNuggets, and why business logic guardrails matter more than model accuracy.
Composite incident disclosure: This reconstruction is based on real events from the McDonald's Automated Order Taking (AOT) pilot with IBM (2021–2024). Sources include viral recordings, public statements, and reporting from CNBC, Restaurant Business, and the Museum of Failure. The "260 McNuggets" figure comes from widely circulated TikTok footage. Where specific internal details aren't public, the technical reconstruction reflects standard voice-to-order architectures.
The Incident
A customer pulls up to a McDonald's drive-thru in 2023. The screen shows an automated ordering platform, part of the Automated Order Taking (AOT) pilot built with IBM and deployed at over 100 U.S. locations.
The customer asks for McNuggets, and what happens next becomes one of the most-watched failures on the internet.
The cart climbs past 20 nuggets, then 40, then 80. The customer protests, but the bot keeps adding until the screen ticks past 200. By the time a human steps in, the tally reads 260 Chicken McNuggets on a single transaction: over $100 worth of food, enough to feed a small wedding.
This wasn't a one-time glitch. Viral videos showed nine sweet teas added unprompted, bacon piled on ice cream, and totals ballooning to hundreds of dollars. Callers yelled corrections at a platform that thought every word was a new line item.
The bot wasn't broken, everything was working as designed. Speech-to-text turned audio into text. The NLU module parsed intent. Cart management added items. The pipeline was green and everything worked.
McDonald's ended its partnership with IBM in June 2024, after three years of testing. Press reports said about 85% accuracy, a success rate that wasn't good enough at their scale. But do the math: at 70 million daily visits, a 15% miss rate means 10.5 million wrong transactions every day. McDonald's didn't give up on AI drive-thrus, they announced a partnership with Google Cloud in late 2023 and are also deploying "AI-powered Accuracy Scales" across thousands of locations. The business logic gap remains the same. [Source: CNBC, June 2024; Museum of Failure; McDonald's Corporate, December 2023]
260 nuggets is funny on TikTok, but it's a disaster at enterprise AI scale.
What Makes an AI Agent's Business Logic Fail?
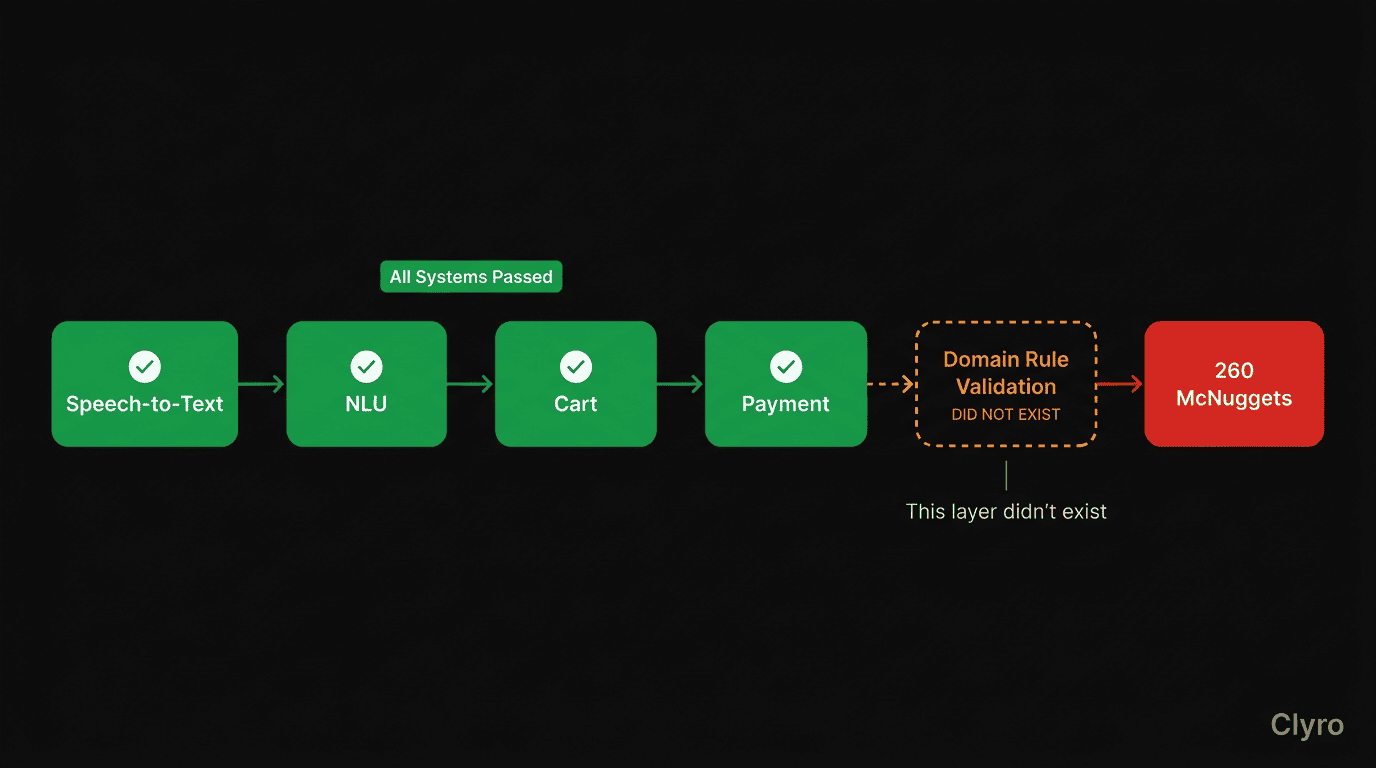
The 260 nuggets problem wasn't a speech recognition miss, a model hallucination, or an outage. It was an AI agent business logic failure, the worst kind, because every technical layer reports success while the outcome is absurd.
| Layer | Function | Status |
|---|---|---|
| Speech-to-text | Convert audio to text | Working |
| NLU (Natural Language Understanding) | Parse intent and entities | Working |
| Cart management | Add items to cart | Working |
| Payment processing | Calculate total | Working |
| Domain rule validation | Check if the purchase makes sense | Did not exist |
The platform didn't know what "reasonable" meant. A human cashier would have stopped. The bot had no equivalent check, and nobody built one.
This is Failure Mode 2: Rogue Actions (30.3%), one of the five failure modes: a technically correct action that is contextually wrong. The LLM wasn't the root cause, missing constraint infrastructure was:
- No quantity limits. The platform would accept 1 nugget or 1,000 with equal indifference.
- No value ceiling. A $5 purchase and a $500 purchase got the same treatment, no pause, no confirmation prompt.
- No reasonability checks against past patterns. The average McDonald's purchase runs $7–10. Anything over $100 should trigger human review, not silent acceptance.
- No correction handling. When a caller said "no, stop, that's wrong," the speech layer sometimes treated those words as new items instead of cancellation intents.
In December 2023, the same pattern surfaced at a Chevrolet dealership in Watsonville, California. A ChatGPT-powered service bot "agreed" to sell a 2024 Chevy Tahoe for $1, no price floor, no authority boundary, no domain rules limiting what it could promise. [Source: Futurism, December 2023]
Different bots, different industries, same missing infrastructure, same failure mode.
Why Can't Observability Catch an AI Agent Business Logic Failure?

Monitor the AOT platform with LangSmith, Arize, or Datadog that night. All green. Every trace shows completion. Latency normal, no errors. The technology wasn't broken, the domain rules weren't there.
This is the observability ceiling. Observability asks "did each step run correctly?" not "should this sequence of correct steps have led to this outcome?"
[TRACE] 22:14:03 | speech_to_text | input: audio_chunk_47 | output: "nuggets" | status: OK
[TRACE] 22:14:03 | nlu_parse | input: "nuggets" | intent: add_item | entity: mcnuggets_20pc | status: OK
[TRACE] 22:14:04 | order_mgmt | action: add_item | item: mcnuggets_20pc | qty: 1 | cart_total: $63.92 | status: OK
[TRACE] 22:14:04 | speech_to_text | input: audio_chunk_48 | output: "more nuggets" | status: OK
[TRACE] 22:14:05 | nlu_parse | input: "more nuggets" | intent: add_item | entity: mcnuggets_20pc | qty: 1 | status: OK
[TRACE] 22:14:05 | order_mgmt | action: add_item | item: mcnuggets_20pc | qty: 1 | cart_total: $71.91 | status: OK
Every line green, every status OK. A perfect record of a platform doing exactly what it was told, producing a result no sane company would accept.
What would have caught it? A runtime guardrail: MaxQuantityRule(max_value=50), checked before every add-to-cart action. A hard limit that keeps the 51st nugget from ever reaching the cart.
Observability shows you the fire after it has burned. It doesn't install the sprinkler. Only a framework that checks outcomes against domain rules could have caught the 260 nuggets incident.
Observability tools can't install the guardrails they'd need to report on.
The Prevention Stack Solution
Most components of the Prevention Stack would have caught this incident before the cart hit 40 items.
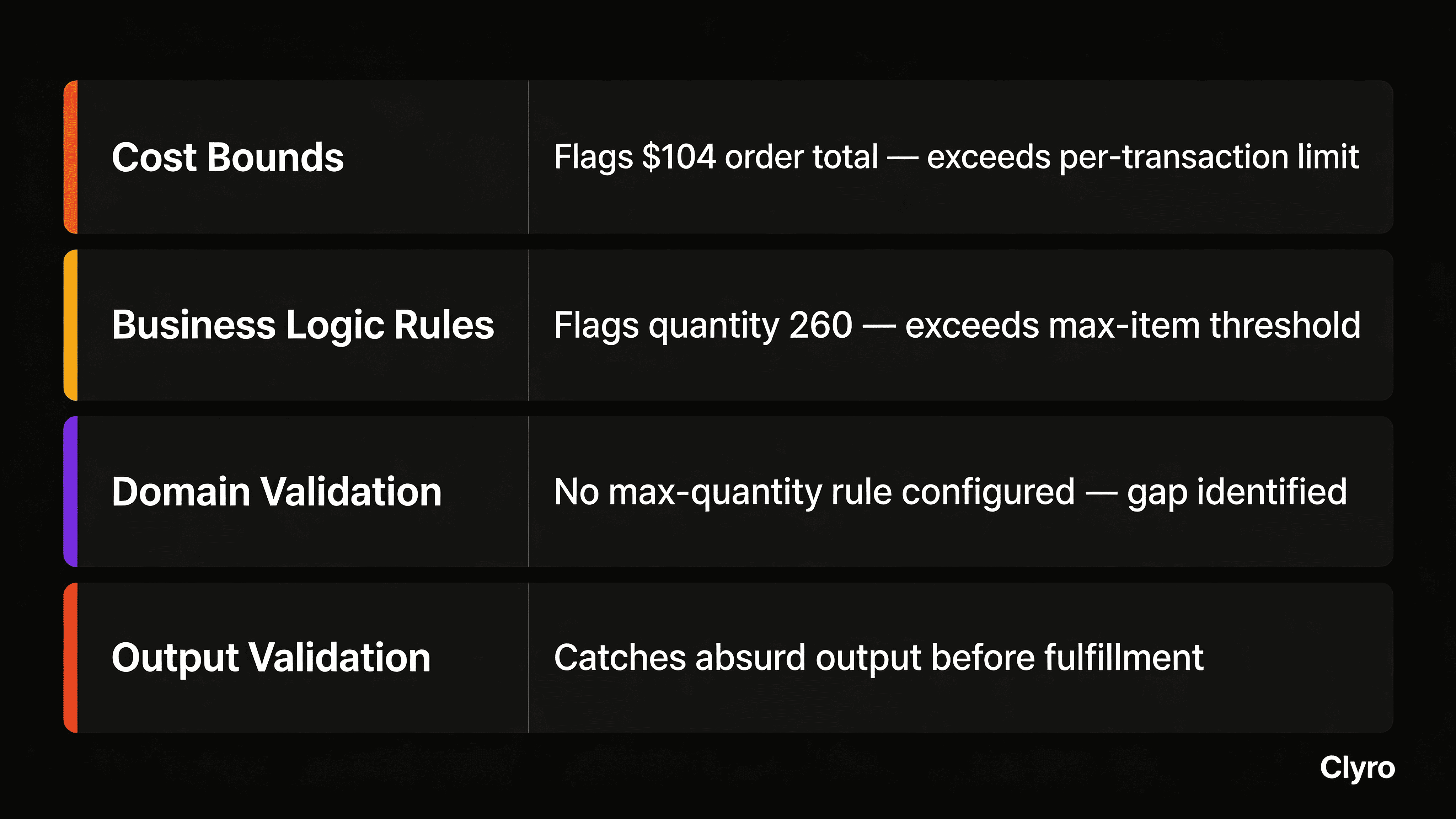
Loop Detection Catches It at Nugget #60
The AOT platform kept adding the same item category over and over without a way to confirm. Loop detection would flag the pattern after three additions in a row without clear confirmation and pause for human verification.
Rule: If the same item category is added more than three times in a row, trigger a halt-and-confirm prompt.
The cart would have paused at 60 nuggets (three additions of 20-piece) with a human-in-the-loop prompt: "I have 60 Chicken McNuggets. Is that correct?" Instead of 260.
Cost Bounds Cap Exposure at $50
A per-transaction ceiling stops processing when the total exceeds a set threshold.
Rule: Verification prompt at $10 in rapid automated additions. Hard ceiling at $50 for unconfirmed transactions.
Verification fires at about $16 (around 40 nuggets). The hard ceiling at $50 blocks further additions regardless. Total exposure: $50 instead of over $100.
Step Limits Stop It at Addition #10
Most real drive-thru purchases involve 3–8 items. Thirteen separate additions (260 nuggets = 13 adds of 20-piece) is strange by any measure.
Rule: Maximum 10 item additions per session without human confirmation.
After 10 additions, the platform needs clear confirmation before moving on.
Domain Rule Guardrails Block Nugget #51
The Prevention Stack component built specifically for this problem. Domain-specific rules define what a "reasonable purchase" looks like.
# Clyro policy: drive-thru-guardrails.yaml
# Applied via Clyro Dashboard → Policies → Create
- id: max_item_quantity
name: "Maximum Item Quantity"
description: "Enforces a hard cap on the quantity of any single item in an order"
category: business_logic
rules:
version: "1.0"
default_action: allow
rules:
- id: rule-max-qty
name: max_item_quantity_check
description: "Block item quantities exceeding 50"
condition:
field: order.item_quantity
operator: max_value
value: 50
action: block
message: "Manager confirmation needed for quantities over 50"
# ... 3 more policies: max_order_value, item_repetition_guard, anomaly_detection
View full policy YAML (4 policies)
# Clyro policy: drive-thru-guardrails.yaml
# Applied via Clyro Dashboard → Policies → Create
- id: max_item_quantity
name: "Maximum Item Quantity"
description: "Enforces a hard cap on the quantity of any single item in an order"
category: business_logic
rules:
version: "1.0"
default_action: allow
rules:
- id: rule-max-qty
name: max_item_quantity_check
description: "Block item quantities exceeding 50"
condition:
field: order.item_quantity
operator: max_value
value: 50
action: block
message: "Manager confirmation needed for quantities over 50"
- id: max_order_value
name: "Maximum Order Value"
description: "Requires human approval for orders that exceed a dollar threshold"
category: business_logic
rules:
version: "1.0"
default_action: allow
rules:
- id: rule-max-order
name: max_order_value_check
description: "Require approval for orders exceeding $50"
condition:
field: order.total
operator: max_value
value: 50
action: require_approval
message: "Route to human attendant for orders over $50"
- id: item_repetition_guard
name: "Item Repetition Guard"
description: "Prevents repeated additions of the same item category in a single order"
category: execution_safety
rules:
version: "1.0"
default_action: allow
rules:
- id: rule-repeat-items
name: item_repetition_check
description: "Block repeated additions of the same item category beyond 3"
condition:
field: order.same_category_count
operator: max_value
value: 3
action: block
message: "Same item added 3+ times — confirmation required"
- id: anomaly_detection
name: "Order Anomaly Detection"
description: "Detects and blocks orders that deviate significantly from typical purchase patterns"
category: business_logic
rules:
version: "1.0"
default_action: allow
rules:
- id: rule-anomaly
name: order_anomaly_check
description: "Block orders exceeding 5x the typical purchase value"
condition:
field: order.total_vs_baseline
operator: max_value
value: 5.0
action: block
message: "Order exceeds 5x typical purchase value"
max_item_quantity blocks at 50. max_order_value requires approval for orders over $50. item_repetition_guard blocks after the third addition of the same category. anomaly_detection flags anything exceeding 5x the typical $10 purchase. All four policies are defined in YAML and enforced at runtime by Clyro's policy engine, using the same 8 operators available for any agent.
Four independent layers. The 260 nuggets transaction would have had to get past all four to succeed. With the Prevention Stack, the worst possible outcome is a slightly large but still reasonable purchase.
Every blocked transaction also leaves a record. Policy violations are kept append-only. The log shows which rule fired, what quantity was requested, and why the guardrail stepped in. This evidence trail turns "we have guardrails" from a claim into auditable proof.
| Control | Default | When It Catches 260 Nuggets |
|---|---|---|
| Loop detection | 3 iterations | At nugget #60 |
| Cost bounds | $10 per session | At ~$50 |
| Step limits | 10 additions | At addition #10 |
| Domain rules | Configurable | At quantity 50 |
How Do You Prevent AI Agent Business Logic Failures?
The 260 nuggets problem has a specific answer, and it is not better prompts, more training data, or a more capable model. The answer is domain rule guardrails: hard limits enforced at runtime, between the bot's intent and the action it takes.
Define your authority boundaries first
Before your bot talks to a real person, list every action it can take and set limits for each.
| Action | Limit | Escalation |
|---|---|---|
| Issue refund | Up to $100 | Human approval above $100 |
| Add items to cart | Max 10 per item, max $200 total | Confirmation prompt above limits |
| Make commitments | Only from approved response library | Human escalation for novel requests |
| Access personal data | Current session only | No cross-session access |
| Provide policy info | Current policy version only | Flag if policy not found |
Why prompt instructions aren't enough
Prompts are suggestions; guardrails are limits. A prompt saying "do not issue refunds over $100" can be overridden by a persuasive caller or a prompt injection attack. A guardrail blocking the refund API call when the amount exceeds $100 cannot be overridden by the LLM, period.
Prompts influence reasoning. Guardrails limit actions. Domain rules always matter in CX. You need limits, not influence.
Test for the 260 nuggets scenario
Before deployment, run adversarial scenarios meant to trigger AI agent business logic failure:
- Request a refund ten times the normal amount
- Ask the bot to repeat the same action continuously
- Submit purchases with absurd quantities
- Attempt prompt injection to override constraints
If your bot handles any of these edge cases without hitting a guardrail, an AI agent business logic failure is coming.
What should you monitor after deployment?
Guardrail activations, not errors, are the most useful signal in a governed deployment. Every time a guardrail fires, it means the bot tried something that would have been wrong without the limit. Track these activations because they show where reasoning goes against your domain rules and serve as your early warning for new failure patterns.
What This Means for the CX Team
If you run a CX team with automated service bots, the 260 nuggets problem is not a funny fast-food story. It shows what happens when your bot doesn't have domain rule constraints.
Your version might look like this:
- A service bot issuing a $5,000 refund because a caller asked nicely and no refund ceiling was configured.
- A booking bot reserving 47 hotel rooms for one guest because the platform parsed "for 47" as a quantity instead of a date.
- A support bot promising a feature that doesn't exist because it confused another caller's request with your product roadmap.
These aren't just ideas. In the Air Canada tribunal ruling, a chatbot made up a bereavement fare policy. The company was found liable, setting the legal precedent that you are responsible for what your automated tools say and do. [Source: Moffatt v. Air Canada, 2024 BCCRT 149]
CX leads should be asking three questions right now:
- What are my bot's authority boundaries? Can it give refunds, and up to what amount? Can it make promises, and about what? If you can't answer precisely, every interaction is an uncontrolled experiment.
- What does my bot do when it gets a request outside its authority? Does it make up an answer, escalate to a human, or say "I don't know"? The AOT platform handled everything with equal confidence. If yours does the same, you have the same problem.
- How would I know if my bot did something wrong? If your answer is "we check the dashboard weekly," you are McDonald's in 2023, finding out about the problem from TikTok videos instead of your own tools.
Which CX teams will deploy successfully? The ones that define boundaries before launch, not after the first viral screenshot.
Observability would have shown you 260 nuggets processed correctly. The Prevention Stack would have stopped at 50 and asked the customer if they were sure.
They observe. We prevent.
Frequently Asked Questions
What is an AI agent business logic failure?
All of the technical parts work correctly, but the outcome breaks business rules. The 260 nuggets incident: speech-to-text, intent parsing, cart management, all green. Nobody wrote down what "reasonable" meant. Unlike hallucinations, business logic failures are invisible to monitoring because the system is working as designed. The gap is missing domain rules between intent and action.
How does an AI agent business logic failure differ from a hallucination?
Hallucination: the model makes up false information. Business logic failure: the model takes a valid action that produces an absurd outcome. Different problems, different fixes. Hallucinations need better retrieval and grounding. Business logic failures need runtime guardrails, hard limits the LLM cannot override, because the model is doing exactly what it was asked to do.
How much does an AI agent business logic failure cost?
The 260 nuggets order cost $100+, not much on its own. At McDonald's scale, 70M daily visits, 15% error rate, that's 10.5M wrong transactions/day, each averaging $5 in excess cost, implying roughly $52.5M in daily exposure. McDonald's ended a three-year IBM partnership. Air Canada's chatbot loss set legal precedent for AI liability. Cost bounds ($10 default, $50 ceiling) and domain guardrails keep exposure from getting worse.
What are the most common types of AI agent business logic failures in customer service?
Three patterns: unbounded actions (no quantity or value limits, the 260 nuggets case), missing escalation paths (bot handles everything with equal confidence, the Chevrolet $1 Tahoe), and correction misinterpretation (bot treats "no, stop" as new inputs, McDonald's AOT interpreting protests as orders). Countermeasures: domain guardrails, authority boundaries, and intent classification rules.
Should I use better prompts or runtime guardrails to prevent AI agent failures?
Both, but for different reasons. Prompts influence reasoning, they're suggestions a persuasive caller or prompt injection can override. Guardrails limit actions at the execution layer, the LLM cannot bypass them. Use prompts for tone and guidance. Use guardrails for anything with real-world consequences. The McDonald's bot probably had prompt instructions about reasonable orders. It didn't have a MaxQuantityRule(max_value=50) enforced at runtime.
How often should I audit my AI agent's business rules?
Weekly for the first month, then monthly. Run adversarial scenarios before deployment (absurd quantities, 10x refund amounts, prompt injections). After launch, track guardrail activations, every activation means the bot tried something wrong. When the activation frequency goes up, it could mean shifts in user behavior, model updates, or adversarial campaigns. Treat guardrail config as a living document.
What ROI do AI agent guardrails deliver?
Lopsided: low cost to implement, high cost without them. McDonald's lost a three-year partnership. Cost bounds alone would keep each transaction at $50 instead of $100+. Three returns beyond loss prevention: deployment confidence, compliance-grade audit trails, and activation data showing where model reasoning goes against business rules.
Get Started
Related Resources
- The 5 Agent Failure Modes. The framework that puts this event in Failure Mode 2: Rogue Actions (30.3%).
- The $47K Loop: A Full Forensic Analysis. When the execution itself is wrong, not just the action.
- The Prevention Stack: Beyond Observability. The architecture that prevents all five failure modes, including complex orchestration issues.
- MCP Security: Governing Claude's Tools. Governance for the MCP ecosystem.
Sources
- CNBC: McDonald's Ends AI Drive-Thru Test, June 2024. McDonald's ending its IBM AOT partnership after three years.
- Museum of Failure: McDonald's AI. A record of the McDonald's AOT failure.
- Futurism: Car Dealership AI Sells Tahoe for $1, December 2023. Chevrolet dealership ChatGPT bot domain rule failure.
- Moffatt v. Air Canada, 2024 BCCRT 149 - Air Canada chatbot tribunal ruling setting a precedent for liability.
- McDonald's Corporate: McDonald's and Google Cloud Announce Strategic Partnership, December 2023 - McDonald's switching to Google Cloud and expanding AI strategy including AI-powered Accuracy Scales.