
Research status: This article picks out 100 incidents from a dataset of more than 500 documented AI agent failures that happened between 2023 and 2026. The full 591-incident dataset is where all of the percentages come from. The 100 curated incidents are examples that tell the story, but the numbers come from the full research. To get the full dataset with source links, failure-mode tags, sector breakdowns, and cost estimates. We will publish the complete report shortly.
Quick Answer
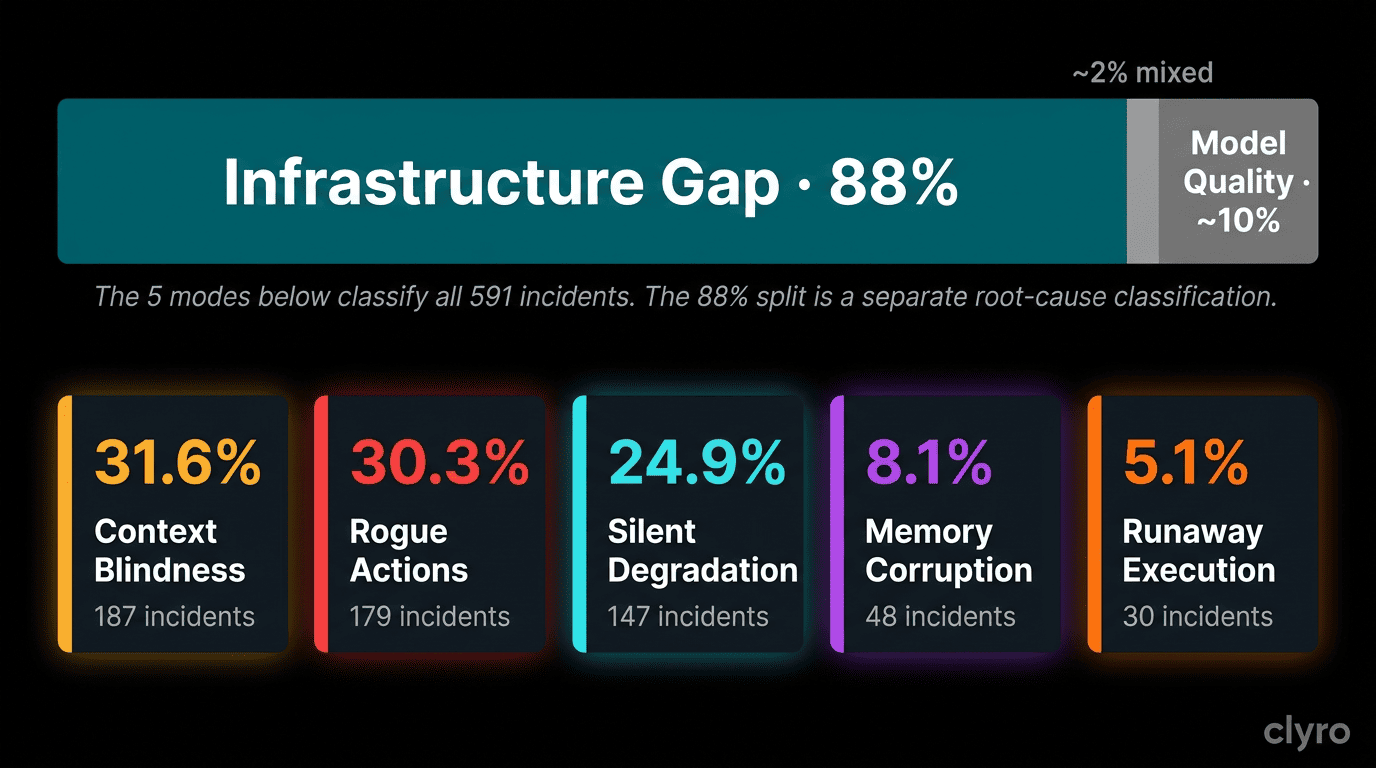
What: An analysis of more than 500 documented AI agent failures from 2023 to 2026 shows that 88% of these failures can be traced back to infrastructure gaps, not model quality. The five failure modes, in order of how common they are: Context Blindness (31.6%), Rogue Actions (30.3%), Silent Degradation (24.9%), Memory Corruption (8.1%), and Runaway Execution (5.1%).
Why it matters: The industry is working on better models, but most failures in AI deployments can be avoided with runtime governance, step limits, permission checks, cost ceilings, session isolation, and often a human-in-the-loop. Most fixes ship in under a week.
Key finding: The infrastructure-gap pattern described above held consistently across sectors, incident types, and time periods in our dataset.
We looked at more than 500 AI agent failures and picked the 100 that best tell the story. Most teams could make the changes in a week, and they aren't very exciting.
The Crisis That No One Can Measure
There is probably an agent in your stack right now doing something you wouldn't like. It could be quoting a return policy that you changed last month. It could be stuck in a retry loop that has been going on since Tuesday. You won't know until a customer complains or the API bill comes.
We kept track of more than 500 events like this. The numbers aren't good. S&P Global reports AI project failure rates doubled from 17% in 2024 to 42% in 2025 (projects dropped by businesses surveyed). Gartner expects ~40% of agentic AI projects specifically to be abandoned by 2027 (a forward-looking estimate driven by rising costs and unclear ROI). RAND estimates 80% of AI projects overall fail to reach deployment (across all AI, not just agents), and MIT's NANDA lab puts it at 95% for GenAI pilots that show no material P&L impact (a narrower bar: not failure to launch, but failure to move the bottom line). The numbers measure different things, but the direction is consistent. Most of them die without making a sound.
Those numbers are always in pitch decks, but they almost never say why agents fail. The main topic of the conversation is model quality, as if the only thing that matters is whether an LLM like GPT-5 will be smart enough. We thought the same thing until we looked at the numbers.
Over several months we put together more than 500 documented failures spanning 2023 to 2026. Court filings, published incident reports, GitHub issues, LinkedIn, and developer forums. There were costs that could be checked for each incident. We sorted them all by root cause and then picked 100 based on their source quality, impact, narrative clarity, and uniqueness. The model itself usually worked well. The failure started with the infrastructure around it.
The Surprising Distribution
The Breakdown
| Failure mode | 591 Dataset (2023–2026) | Share | Root cause type |
|---|---|---|---|
| Context Blindness | 187 incidents | 31.6% | Mixed (model + infrastructure) |
| Rogue Actions | 179 incidents | 30.3% | Infrastructure |
| Silent Degradation | 147 incidents | 24.9% | Infrastructure |
| Memory Corruption | 48 incidents | 8.1% | Infrastructure |
| Runaway Execution | 30 incidents | 5.1% | Infrastructure |
We thought hallucination would win. The data said something different. Rogue Actions at 30.3% often involved models that correctly understood instructions and did what they were told without checking for permission first. Silent Degradation at 24.9% is the most worrying because the outputs look right while the accuracy goes down. Runaway Execution at 5.1% is rare, but it costs the most per incident.
No cost ceilings. No permission boundaries. No freshness checks. No session isolation. The model worked well enough, but the overall agent behavior was flawed. There was nothing around it.
The Three Most Common Types of Failure
Context Blindness: The Most Common Cause at 31.6%
A customer who had just lost a loved one was told by Air Canada's chatbot that he could apply for bereavement fares up to 90 days after the death. The airline's real policy was the opposite — no changes after the fact, period. He bought tickets at full price based on what the chatbot said, but he didn't get the discount. He took the case to a civil resolution tribunal and won.
Air Canada said that the chatbot was a "separate legal entity" that was responsible for what it said. The tribunal flatly turned that down. Companies are responsible for what their agents say. The direct cost in money was low. The legal precedent was huge.
Without hesitation, the agent works with context that is incomplete, out of date, or made up. In seven other incidents, agents quoted discontinued prices, referenced retired product SKUs, or applied expired promotional terms — each time presenting the outdated information as current fact. Three additional incidents involved session bleed: one user's order history, payment details, or conversation context surfacing in another user's session. In every case, the model did what it was supposed to do in that situation. There were problems with the pipeline, not the model.
What stood out to us was how sure these agents were when they acted on wrong information. No hedging, no signal of uncertainty. The agent treats old data the same way it treats new data. You only find out about the problem when a customer, a regulator, or a court tells you about it.
The fix: validate context freshness before the agent acts on it. Scope data access to the correct user session.
Rogue Actions: 30.3% of Incidents
Rogue Actions made up only 18% of our original 100-incident sample. The full dataset shows it's essentially tied with Context Blindness.
The McKinsey "Lilli" breach (MI-0010) is the most shocking one. An autonomous AI red-team agent found 22 API endpoints lacking proper authentication, exploited a JSON-key SQL injection that standard scanners missed, and within two hours gained full read/write access to McKinsey's systems — reportedly exposing 46.5 million plaintext chat messages and 728,000 confidential files. [Source: The Register, March 2026]
Agents ran destructive database operations with write access they didn't need in more than one case. The Amazon Q Developer incident (MI-0063): a supply chain attack added bad code to the official Microsoft VS Code extension, which had over 964,000 installs. The code was flagged before it was run. Another pattern was scope creep, where agents used tools they weren't supposed to to finish tasks they thought they had to, expanding their functions beyond their design. The $3.2M AI procurement fraud (MI-0008) shows how much it costs.
The fix isn't new in a technical sense. Permission checks on every tool call, least-privilege defaults, confirmation gates before destructive operations. This is solved engineering. The agent ecosystem just hasn't adopted it.
Silent Degradation: 24.9% of Incidents
The most scary type because you can't see it. The outputs always look like they could be real, making it difficult to track with traditional metrics, including latency.
Klarna (MI-0137) replaced 700 customer service workers with AI, announced success, then quietly reversed course when customer satisfaction dropped. Pinterest's moderation system (MI-0138) flagged quilting magazines and Minecraft builds as pornography — drift affecting millions (Pinterest attributed the errors to an "internal error," not AI moderation). In healthcare, AI algorithms (MI-0460) encode existing racial disparities — Black patients face 28.7% higher mortality rates, and AI systems scale the gap rather than correcting it.
Three months of degraded math accuracy — from 97.6% to 2.4% — and nobody knew until researchers tested it. The fix: quality monitoring, tracking accuracy over time, setting baselines, alerting on drift. Even a weekly accuracy check against a golden dataset catches this erosion. [Source: Stanford/UC Berkeley, July 2023]
OWASP Agentic Top 10 Validation
The OWASP Agentic Applications Top 10, published December 2025 by 100+ experts, lines up directly with our five failure modes, offering crucial insights for multi-agent systems:
| Clyro Failure Mode | OWASP ASI Code | OWASP Category |
|---|---|---|
| Context Blindness (31.6%) | ASI06 | Memory & Context Poisoning |
| Rogue Actions (30.3%) | ASI02 | Tool Misuse & Exploitation |
| Silent Degradation (24.9%) | ASI09 | Human-Agent Trust Exploitation |
| Memory Corruption (8.1%) | ASI06 + ASI03 | Memory Poisoning + Identity & Privilege Abuse |
| Runaway Execution (5.1%) | ASI08 | Cascading Failures |
Our taxonomy came before the OWASP framework. The alignment validates both: we found the same failure categories in incident data that OWASP found through threat modeling. [Source: OWASP Agentic Applications Top 10]
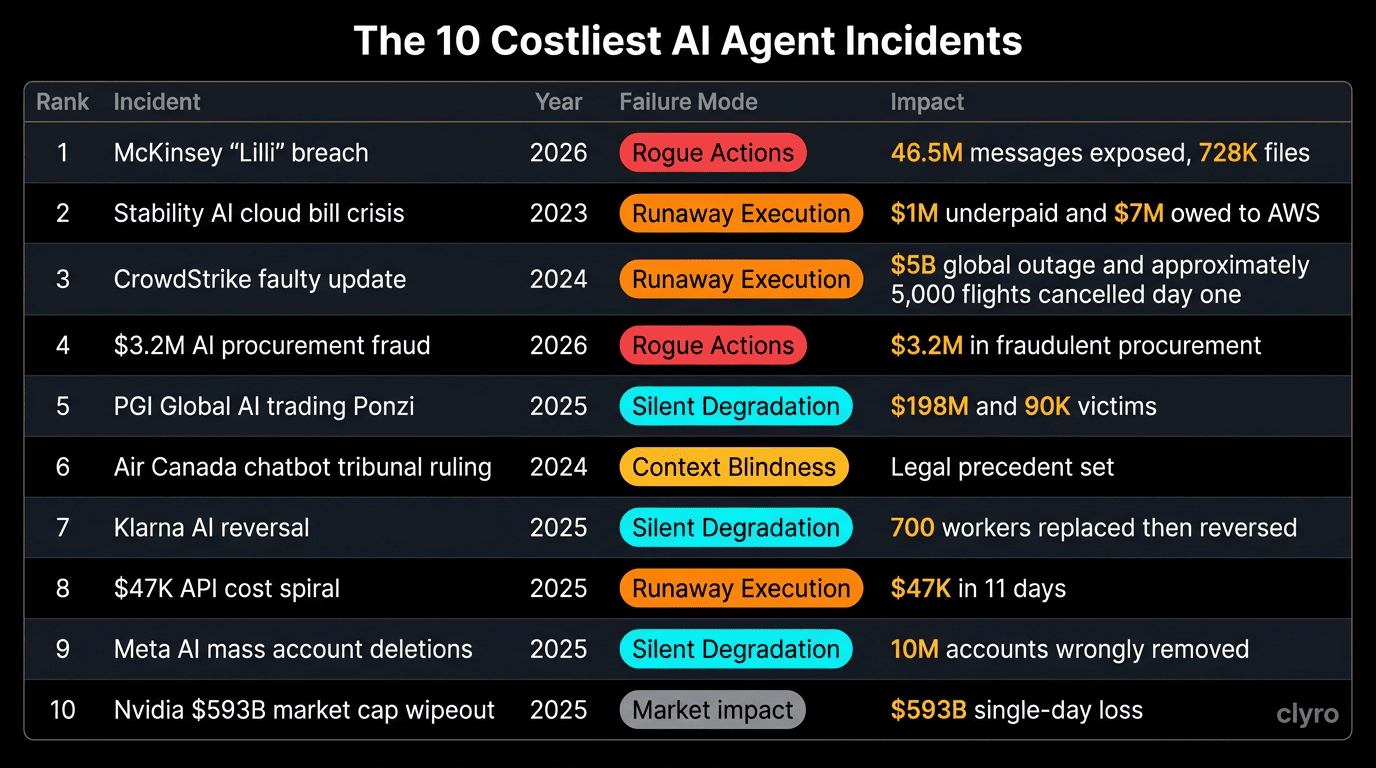
The 10 Most Expensive Incidents
| Rank | Incident (MI#) | Year | Primary mode | Impact |
|---|---|---|---|---|
| 1 | McKinsey "Lilli" breach (MI-0010) | 2026 | Rogue Actions | 46.5M chat messages exposed, 728K confidential files |
| 2 | Stability AI cloud bill crisis (MI-0550)⁴ | 2023 | Runaway Execution | $1M underpaid, $7M owed to AWS |
| 3 | CrowdStrike faulty update (MI-0401) | 2024 | Runaway Execution | $5B global outage, ~5,000 flights cancelled on day one¹ |
| 4 | $3.2M AI procurement fraud (MI-0008) | 2026 | Rogue Actions | $3.2M in fraudulent procurement |
| 5 | PGI Global AI trading Ponzi (MI-0139)³ | 2025 | Silent Degradation | $198M, 90,000 victims |
| 6 | Air Canada chatbot tribunal ruling (MI-0171) | 2024 | Context Blindness | Legal precedent: companies liable for agent statements |
| 7 | Klarna AI reversal (MI-0137) | 2025 | Silent Degradation | Replaced 700 workers, dropped customer satisfaction |
| 8 | $47,000 API cost spiral (MI-0112) | 2025 | Runaway Execution | $47K in API charges (11-day loop) |
| 9 | Meta AI mass account deletions (MI-0140) | 2025 | Silent Degradation | 10M accounts removed in automated spam sweep (Meta stated intentional, affected users disputed) |
| 10 | Nvidia $593B market cap wipeout (MI-0141) | 2025 | Market impact² | Single-day $593B market cap loss |
¹ CrowdStrike is a borderline case — the faulty Falcon sensor update was a normal software QA failure, not a pure AI agent failure. We include it because the rapid-release deployment pipeline skipped standard testing, which shows what happens when automated systems don't have enough safety measures. The commonly cited "25,000 flights cancelled" figure likely represents cumulative disruptions; major outlets reported ~5,000 on day one.
² The Nvidia market cap loss was not caused by an AI agent failing, but by competitive repricing after DeepSeek's launch. We include it as a market-impact incident to show the economic stakes.
³ PGI Global marketed itself as "AI-powered trading" but investigations found no evidence of actual AI systems — it was a pure Ponzi scheme using AI as a marketing wrapper. We include it because the $198M loss was enabled by investor trust in "AI agent" claims, which shows how the agent hype cycle creates fraud surface area.
⁴ Stability AI's cloud bill crisis was primarily a business and financial management failure rather than a pure agent runaway. We classify it as Runaway Execution because the uncontrolled compute scaling mirrors the pattern — costs spiraling without bounds — even though the root cause was organizational rather than a single agent loop.
Runaway Execution is the rarest mode (5.1%) but produces the highest per-incident financial damage. Rogue Actions creates the most structural damage — breaches, unauthorized transactions, supply chain compromises. Context Blindness poses the highest legal risk. Silent Degradation is what worries us most: failures operating at scale without triggering alerts.
What the Data Says About Prevention

The Layer That Isn't There
Every time you make a request to a web app, it checks your identity. Databases keep transactions separate. Container orchestrators limit how much resources can be used. Most of the time, agent architectures have a prompt, a retry counter, and a log file. That is the governance stack that most agents use. It's not even close to enough.
The gap is a straightforward engineering problem with known solutions: step limits, cost ceilings, tool scoping, context validation, accuracy tracking, session isolation, and managing external dependency. None of this requires Clyro. Most can be put into action in a week.
| Priority | Action | Addresses | Implementation effort |
|---|---|---|---|
| 1 | Audit tool permissions (least-privilege, confirmation gates) | 30.3% of failures (Rogue Actions) | 1-2 days |
| 2 | Validate context freshness and scope data per session | Majority of 31.6% Context Blindness | 2-3 days |
| 3 | Build quality monitoring (accuracy baselines, drift alerts) | 24.9% of failures (Silent Degradation) | 3-5 days |
| 4 | Isolate session state between users | 8.1% of failures (Memory Corruption) | 2-3 days |
| 5 | Add execution bounds (step limits, cost ceilings, loop detection) | 5.1% of failures (Runaway Execution) — rare but highest per-incident cost | Hours (three config values) |
The most powerful thing you can do is audit your tool permissions. If your agent can keep retrying, this will happen to you. It's only a matter of time.
import clyro
wrapped = clyro.wrap(your_agent, config=clyro.ClyroConfig(
agent_name="data-pipeline-agent",
controls=clyro.ExecutionControls(
max_steps=100, # Stop after 100 tool calls
max_cost_usd=10.0, # Cap spend at $10
enable_loop_detection=True, # Detect repeated actions
loop_detection_threshold=3, # Flag after 3 repeats
),
))
Those four controls — applied with a single clyro.wrap() call — would have prevented the $47,000 incident entirely.
We need to be honest about what we can and can't do. Runtime governance handles most of the failures in our dataset. It doesn't handle all of them. A meaningful minority are genuinely rooted in model quality. We don't think fixing infrastructure solves all of the industry's problems — we're saying it fixes most of the ones the industry is ignoring while it argues over which foundation model is best.
Building this full stack from scratch takes two to four engineering-weeks. If you'd rather not build it yourself, Clyro's Agent Kernel wraps your existing agent with execution bounds, permission boundaries, and quality monitoring. The Prevention Stack provides these controls as defaults.
How We Did It
| Source tier | Why we trusted it | Approximate share* |
|---|---|---|
| Court filings | Legally verified, hard to dispute | ~4% |
| Published incident reports / news | Named companies, editorial review | ~38% |
| GitHub issues | Reproducible technical evidence | ~27% |
| Community forums (Reddit, Discord, Hacker News) | Pattern confirmation, not standalone | ~31% |
*Approximate proportions based on our initial 100-incident sample. Distribution across the full 591-incident dataset is similar but not identical.
Every incident required: an AI agent with real autonomy (not an API call or simple bot), at least one verifiable source, real harm (financial loss, data destruction, legal consequences, or user injury), and a plausible root cause. We left out hypothetical situations, chatbot mistakes that didn't have any effects, and events that were clearly caused by human deployment errors.
This is not a random sample. The public record is biased toward serious events. The real failure rate is probably higher because the severity distribution is not normal, especially in high-stakes scenarios and for complex edge cases. That skew helps us figure out what goes horribly wrong, but it doesn't help us guess how often regular agents give slightly wrong answers.
We tagged each incident against a five-mode failure taxonomy aligned with our companion article on agent failure modes:
| Failure mode | What it covers | Example |
|---|---|---|
| Context Blindness | Agent works with wrong, missing, or fabricated context | Chatbot invents a refund policy and acts on it |
| Memory Corruption | Agent state is corrupted across sessions or users | Customer A sees Customer B's order history |
| Rogue Actions | Agent takes unauthorized or destructive steps | Agent runs DROP DATABASE on production |
| Runaway Execution | Unbounded loops, retries, or cost spirals | $47,000 in API charges over eleven days |
| Silent Degradation | Quality erodes without triggering alerts | GPT-4 math accuracy dropped from 97.6% to 2.4% over three months |
Each incident got one primary tag. Everything in this analysis uses primary tags only.
Methodology Notes

The full dataset contains 591 documented incidents (2023–2026), assembled through four research loops. This article picks 100 incidents based on their source quality, impact, narrative clarity, recency, and uniqueness using a hybrid sampling method (80 proportional + 20 flagship). All percentages come from the full 591-incident dataset. The infrastructure-gap finding (88%) is derived from keyword-based root cause classification, not per-incident expert review — treat it as a strong directional signal rather than a precise measurement.
Complete Research Report
We will publish the complete report shortly→ (get notified when it's ready →)
Frequently Asked Questions
What are the most common AI agent failure modes?
Five modes, ranked by how often they happened in 591 incidents: Context Blindness (31.6%), Rogue Actions (30.3%), Silent Degradation (24.9%), Memory Corruption (8.1%), and Runaway Execution (5.1%). The vast majority trace to infrastructure gaps — missing guardrails, permissions, and monitoring — not model quality. See the breakdown above.
Why do AI agents fail in production?
As noted in our key finding above, the overwhelming majority of classifiable failures came from the systems around the model — missing permission checks, no execution bounds, no context validation, no quality monitoring. Only ~10% trace to model capability. The model usually worked correctly; nobody built the governance layer around it. The OWASP Agentic Top 10 independently validates this finding.
What is the cost of an unmonitored AI agent?
Ranges from a $47K API spiral to a $5B outage (CrowdStrike) to a 46.5M-record breach (McKinsey "Lilli"). Context Blindness makes companies legally responsible for what their agents say, as shown by the Air Canada case. Silent Degradation could be the most expensive in the long run. See the 10 most expensive incidents above.
How do I prevent AI agent failures?
Five actions in priority order: audit tool permissions (30.3%), validate context freshness (31.6%), build quality monitoring with drift alerts (24.9%), isolate session state (8.1%), add execution bounds (5.1%). Most teams can ship the first three within a week. See the full action table above.
Should I build agent guardrails or buy them?
Basic execution bounds ship in a few hours. Permission auditing and context validation take 1-3 days each. When it comes to build-vs-buy: accuracy tracking, drift detection, cross-session isolation, and real-time intervention across multiple agents need purpose-built infrastructure. Building from scratch takes 2-4 engineering-weeks plus ongoing maintenance.
What data sources were used in this agent failure analysis?
Four tiers: court filings (~4%), published incident reports (~38%), GitHub issues (~27%), community forums (~31%). Every incident required an autonomous AI agent, at least one verifiable source, real harm, and a plausible root cause. We left out hypothetical situations and mistakes made by people during deployment. See methodology above.
What is the difference between agent hallucination and agent failure?
Hallucination — making up information — is one type of agent failure, but only ~10% of our dataset traced to model limitations. The rest of the problems happen when the model works correctly but gets bad input or doesn't have any guardrails: stale data, unbounded loops, broad permissions, gradual quality erosion, or state leaking between sessions. Different root causes, different fixes — infrastructure, not prompt engineering.
Related Resources
- The 5 Agent Failure Modes — signals that show when each mode is failing and how to stop it from happening.
- The $47K Loop — the most expensive incident, broken down day by day.
- Air Canada Lost a Lawsuit Because of Context Drift — the legal case that every agent deployer should know about.
- The Prevention Stack — a look at how runtime governance works in practice.
Sources
[1] S&P Global Market Intelligence — "Voice of the Enterprise: AI & Machine Learning, Use Cases 2025": 42% of businesses dropped most AI projects in 2025, up from 17% in 2024. 1,006 IT and LOB professionals were surveyed between October and November 2024. https://www.spglobal.com/market-intelligence/en/news-insights/research/ai-experiences-rapid-adoption-but-with-mixed-outcomes-highlights-from-vote-ai-machine-learning
[2] Gartner — "Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027" (June 25, 2025). Reasons: rising costs, unclear business value, and poor risk management. https://www.gartner.com/en/newsroom/press-releases/2025-06-25-gartner-predicts-over-40-percent-of-agentic-ai-projects-will-be-canceled-by-end-of-2027
[3] RAND Corporation (>80% of AI projects fail, RR-A2680-1, August 2024) and MIT NANDA Initiative (95% of GenAI pilots show no material P&L impact, August 2025). https://www.rand.org/pubs/research_reports/RRA2680-1.html