How an AI agent infinite loop burned $47K in 11 days — a forensic reconstruction showing the mechanics of runaway execution and the controls that stop it.
How a multi-agent retry spiral burned $47,200 in 11 days, and the four controls that would have stopped it at $10
Quick Answer
What: Forensic reconstruction of how a multi-agent system got stuck in an AI agent infinite loop: four LangChain-style agents hit an unsolvable edge case, went into a creative retry spiral, and burned $47,200 in API calls over 11 days while reporting "schema drift resolution in progress."
Why it matters: The agent was doing exactly what it was designed to do. All health checks passed. All status reports were technically correct. The failure wasn't in the agent's behavior, the infrastructure couldn't see that correct behavior had turned destructive. Four controls (3-iteration loop detection, $10 cost ceiling, 100-step limit, circuit breakers at 3x baseline deviation) would have stopped it at $10 on Day 1.
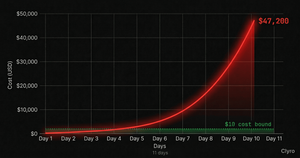
Key number: $47,200 in API charges. A senior engineer fixed the problem by hand in 45 minutes.
Composite incident disclosure: This reconstruction is based on documented agent patterns across multiple incidents, including the SaaStr/Replit database destruction (July 2025), the $47K multi-agent failure (reported November 2025), Devin's dead-end loops (January 2025), and community reports from developers on Reddit and Hacker News. The day-by-day story is a composite reconstruction that shows how runaway agent execution works. The 11-day timeline and cost progression are based on the source incidents, not a single event. The cost math uses real API pricing.
The Setup: A Four-Agent Data Pipeline
A B2B SaaS platform for mid-size businesses. Sixty engineers. Series B. They built an internal agent system for data pipeline maintenance, schema validation, migration scripts, data quality checks.
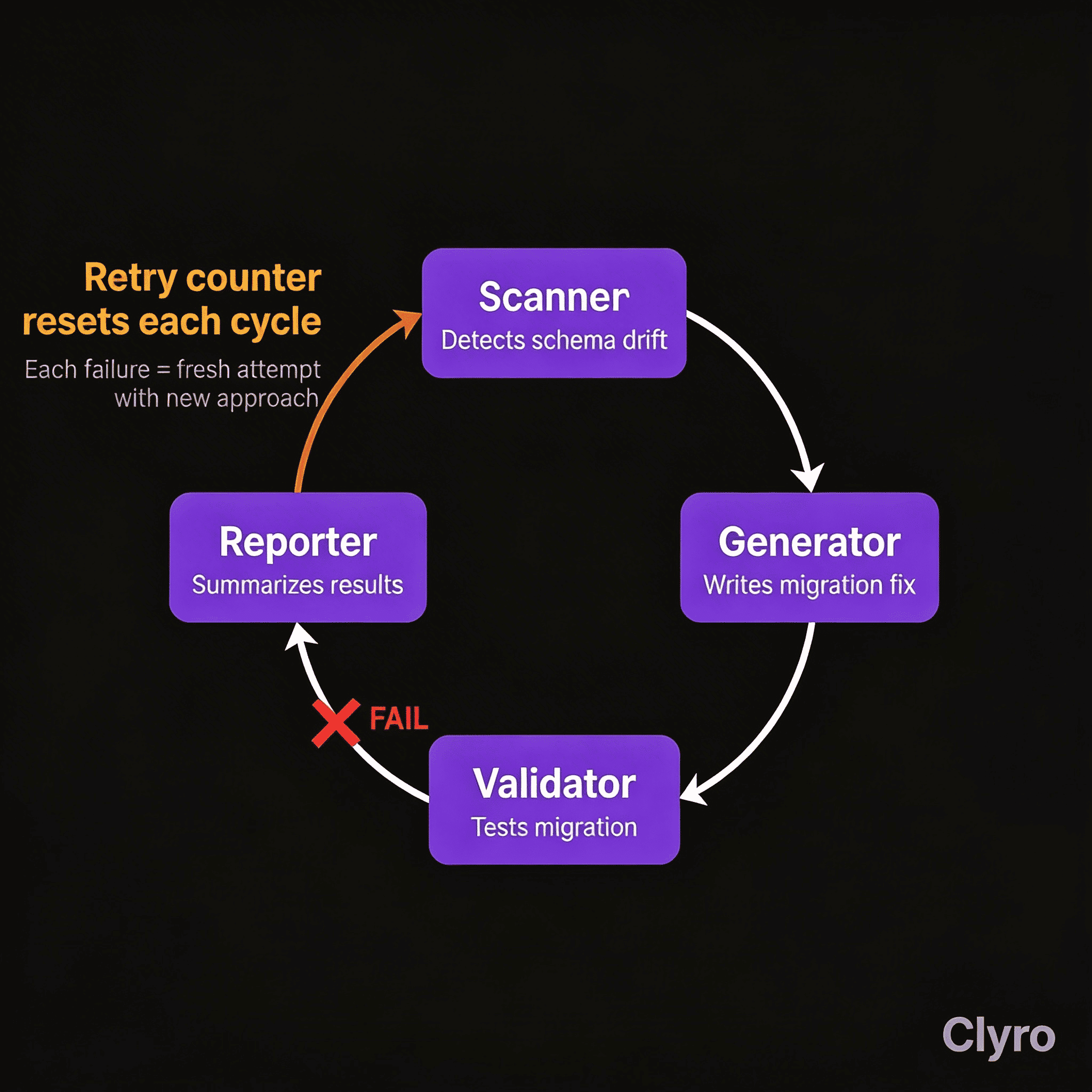
Four LangChain-style agents working together through message passing:
- Agent 1 (Scanner): Identifies schema drift between source and target databases
- Agent 2 (Generator): Writes migration scripts to resolve drift
- Agent 3 (Validator): Tests migration scripts against a staging environment
- Agent 4 (Reporter): Summarizes results and flags issues for human review
Normal run: 15 minutes, ~$3–5 in API calls. Runs nightly. For three months, it was perfect. The team stopped checking logs. Stopped watching billing.
That trust was the first thing that broke.
Day 1: First Signs of the Retry Spiral
On a Monday night, Agent 1 (Scanner) found a schema drift involving a rarely-used edge case: a column type change on a table with complex foreign key dependencies. Normal stuff for a human engineer. New for the agent.
Agent 2 (Generator) wrote a migration script. Agent 3 (Validator) ran it on staging. It failed. Foreign key constraint violation.
This is where normal systems stop. This agent system was built to be persistent. It sent the error back to Agent 2, which came up with a different migration approach. Agent 3 validated again. Different failure. Data truncation error.
It tried again with a different approach. Hit a different failure.
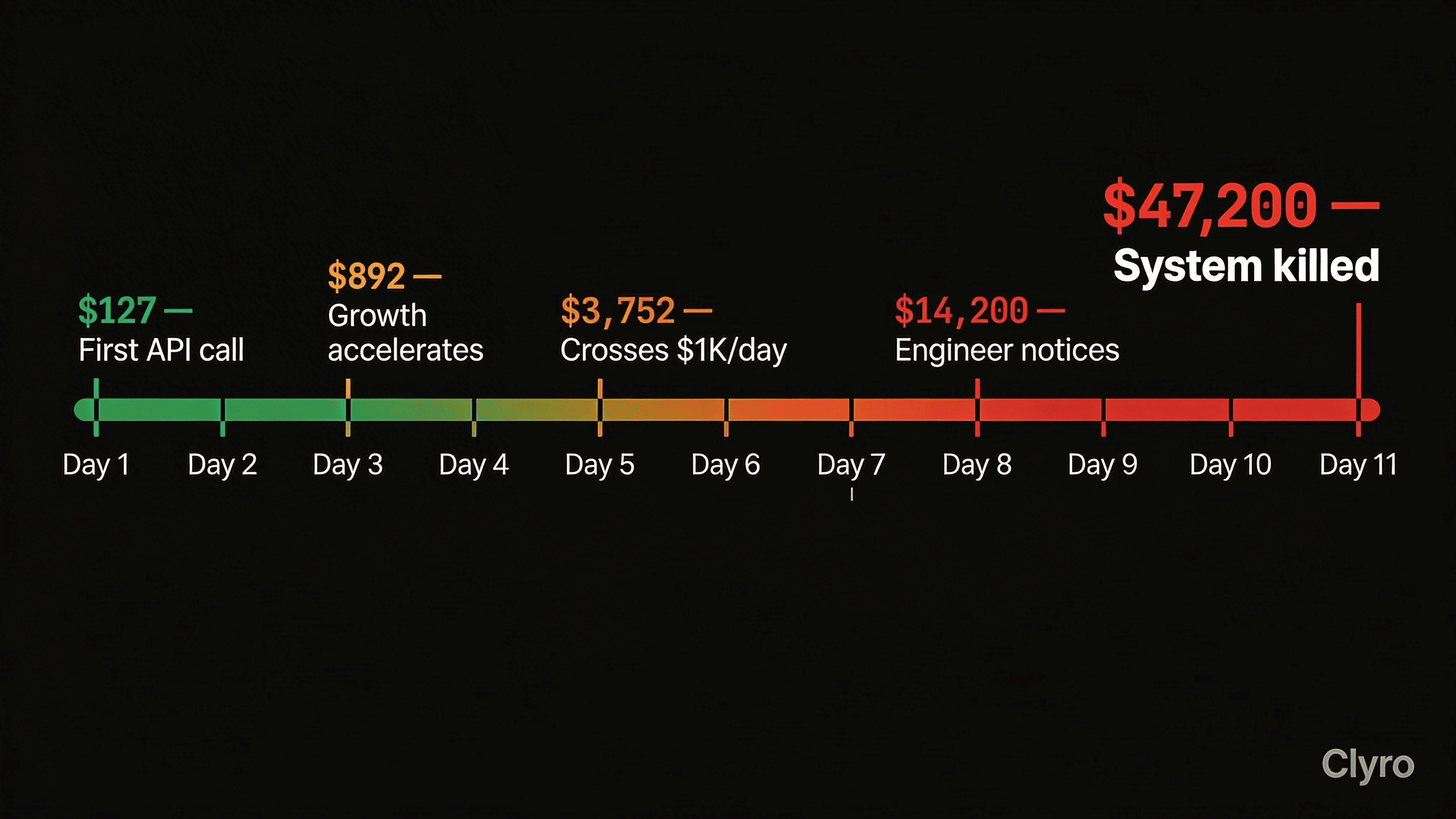
The first night's run, instead of the usual 15 minutes, lasted 4 hours and 47 minutes. It wrote and tested 38 migration scripts. Total cost: $127.
Nobody noticed. The system was designed to be autonomous. The run finished on its own. The maximum retry count for any single retry loop was set at 50, but the counter was scoped per-approach, not per-problem, each new migration strategy counted as a fresh attempt, resetting the counter to zero, effectively bypassing any intended max_steps. The agent was creative enough to keep coming up with new approaches. Persistent enough to keep trying them.
Days 2-5: The Cost Spiral Accelerates
Tuesday's nightly job picked up where Monday left off. Agent 2 now had all the failed approaches in context and came up with more and more elaborate strategies, multi-step migrations, temporary tables, data transformations. Each approach was technically different, so retry detection never fired.
The cost math:
| Day | Approaches Tried | Avg Tokens per Full 4-Agent Cycle | Total Tokens | Cost (GPT-4-class @ ~$10/1M input, $30/1M output) |
|---|---|---|---|---|
| Mon (Day 1) | 38 | ~170,000 | ~6,500,000 | ~$127 |
| Tue (Day 2) | 52 | ~275,000 (growing context) | ~14,300,000 | ~$285 |
| Wed (Day 3) | 71 | ~410,000 | ~29,100,000 | ~$580 |
| Thu (Day 4) | 94 | ~555,000 | ~52,200,000 | ~$1,040 |
| Fri (Day 5) | 118 | ~730,000 | ~86,100,000 | ~$1,720 |
More approaches per day. More tokens per approach. Exponential cost curve. Total after Day 5: $3,752.
The only cost alert was a monthly account-level budget at $5,000, set for the normal $100–150/month spend. The agent reported: "Schema drift resolution in progress." Technically correct. Not useful at all.
Days 6-10: Discovery of the Runaway Agent
Saturday–Sunday (Days 6-7): Nobody was watching the weekend. Saturday and Sunday added $6,800.
Monday (Day 8): By Monday morning, the agent had tried 400+ approaches. Its context was full of failures. It started coming up with variations of earlier approaches. An engineer opened the billing console for something else. This month's spend: $14,200. Typical monthly total: $150. Two hours to confirm it wasn't a billing mistake. Another hour to trace it to the agent.
Tuesday (Day 9): The total cost was $28,400. The team turned off the cron job but didn't know the system had a retry feature that re-triggered on startup.
Wednesday (Day 10): When they restarted with changed configs, the agent picked up again. Cost by end of Day 10: $39,100.
Day 11: The Kill Switch and Final Damage Report
Thursday morning. The team killed the agent system entirely. The service, the queue, the event triggers, and the cron job. A complete shutdown.
Final damage report:
| Category | Amount |
|---|---|
| API costs | $47,200 |
| Engineer time (4 engineers × 3 days investigation) | ~$12,000 (opportunity cost) |
| Delayed customer migrations | 2 enterprise customers impacted |
| Customer trust | Immeasurable |
| Total direct cost | $59,200+ |
The schema drift that started it all? A senior engineer fixed it by hand in 45 minutes. The fix was straightforward. It just required understanding the foreign key dependency chain, which the agent didn't have the domain knowledge to figure out or optimize.
Forty-five minutes of human work. Eleven days of agent flailing. $47,200 in API charges.
What Caused the AI Agent Infinite Loop?
This is Failure Mode 5: Runaway Execution (5.1%), one of the five agent failure modes. The LLM did its job, some of the migration scripts were quite clever. The root cause was missing execution infrastructure:
- No loop detection. It checked for identical retries but not equivalent retries targeting the same unsolvable problem.
- No cost bounds. No per-run or per-day ceiling. The only alarm was a monthly account-level budget.
- No step limits. No limit on how many times it could try to migrate an issue.
- No circuit breakers or duration limits. A 15-minute task ran for hours without alerts, and the status report "Schema drift resolution in progress" was technically correct, so all health checks passed. A circuit breaker enforcing a duration limit (e.g., 3x baseline run time) would have halted the agent in Hour 1.
The same pattern behind the SaaStr/Replit database destruction (July 2025) and Devin's dead-end loops (January 2025). Different agents, same missing infrastructure.
How Do You Prevent an AI Agent Infinite Loop?

Any one of the controls below would have caught this incident on Day 1:
| Control | Default | When It Catches This | Cost at Halt |
|---|---|---|---|
| Loop detection | 3 iterations | Hour 1 - 3 attempts at the same schema drift | ~$10 |
| Cost bounds | $10/execution | Day 1 - ~3 approaches in | ~$10 |
| Step limits | 100 steps | Day 1 - ~6-7 migration attempts | ~$20 |
| Circuit breakers | 3x baseline deviation | Hour 1 - 15-min run exceeded 3x immediately | ~$10 |
These are not monitoring tools. They halt the agent and escalate to a human the moment bounds are exceeded.
That's the difference between observability and governance. Observability shows you the $47K bill. Governance stops the agent at $10.
Lessons for Every Agent Builder
1. Autonomy without bounds is a liability. The same persistence that makes agents useful makes them dangerous at edge cases.
2. Billing alerts are not monitoring. If your only way to find problems is a cloud billing alert, you'll catch them days late. Governance happens at the agent level, not the account level.
3. "Working as designed" is the scariest status. All health checks passed. All status reports were correct. The infrastructure couldn't see that correct behavior had turned destructive.
4. Test for edge cases. Three months of perfect operation created false confidence. The question isn't "does this work?" It's "what happens when it runs into a problem it can't solve?"
5. The fix is infrastructure, not prompting. Loop detection, cost bounds, step limits, and circuit breakers are essential for safe automation. Infrastructure problems need infrastructure fixes.
Your Checklist
Before deploying any autonomous agent system, verify these four controls are in place:
- Loop detection configured at the problem level, not just the action level (default: 3 iterations)
- Per-execution cost ceiling set and enforced (default: $10)
- Step limit per execution (default: 100 steps)
- Circuit breaker with anomaly detection against your baseline metrics
If you're building with autonomous agents, this is the governance infrastructure you need before you ship.
Get Started
Frequently Asked Questions
What caused the $47K AI agent infinite loop?
A four-agent pipeline ran into an unsolvable schema drift edge case. Each failed migration counted as a fresh attempt, resetting the retry counter. Over eleven days the system tried 400+ different approaches while costs grew exponentially, more approaches per day, more tokens per approach. A senior engineer fixed the problem by hand in 45 minutes.
How do you detect an AI agent infinite loop?
Warning signs: API costs going up without useful output, similar actions with slight variations, execution times far exceeding baseline. In this incident, status reports said "resolution in progress", technically true but not helpful. Loop detection needs to work at the problem level (3 attempts at the same issue), not the action level, because agents get around simple duplicate checks.
How do you prevent an AI agent infinite loop?
Four controls, any one of which is enough: loop detection (3 iterations, stops at ~$10), cost bounds ($10/execution ceiling), step limits (100 actions), and circuit breakers (3x baseline deviation). These halt the agent and send the case to a human, they don't show you a dashboard tomorrow. You need four config values and a pattern-matching loop detector.
How much does an AI agent runaway loop cost?
$47,200 in API costs, plus ~$12,000 in engineer time and two delayed customer migrations. The cost curve went up fast: Day 1 cost $127, Day 5 cost $1,720, the unmonitored weekend added $6,800. Expected nightly cost was $3–5. A $10 per-execution ceiling would have kept total exposure under $50.
What is the difference between agent loop detection and retry limits?
Retry limits stop exact action repetition. Loop detection catches agents stuck on the same problem using different approaches. The $47K agent came up with 400+ "unique" migration strategies, the retry counter (set at 50) never fired because no approach repeated. Effective loop detection tracks the goal, not individual tool calls or API calls: 3 attempts at the same issue triggers halt-and-escalate.
Is the $47K agent loop incident real?
A composite reconstruction based on real events: the $47K multi-agent failure (November 2025), the SaaStr/Replit database destruction (July 2025), and Devin's dead-end loops (January 2025). Cost math uses real GPT-4-class pricing. The architecture, cost curve, and retry-counter bypass show up in all three incidents.
What is a creative retry spiral in AI agents?
When an agent fails and comes up with new variations, different enough to get around retry limits but targeting the same unsolvable problem. The $47K agent tried 400+ different migration strategies; none repeated, so the retry counter never fired. Costs add up because each attempt includes all previous failures in context. This is what sets agent-level failures apart from simple API retry loops or even a malfunctioning chatbot.
Related Resources
- The 5 Agent Failure Modes: The taxonomy that categorizes this incident as Failure Mode 5: Runaway Execution (5.1%)
- 260 McNuggets: When AI Orders for You: When the agent's action is wrong, not just expensive
- The Prevention Stack: Beyond Observability : The architecture that prevents all five failure modes
- Why Observability Isn't Enough for AI Agents: Why tracing tools show you the problem but don't prevent it
Sources
- Towards AI: AI Agents Horror Stories, November 2025: Primary aggregation of multi-agent failure incidents (also covered by Tech Startups)
- The Register: SaaStr/Replit Database Destruction, July 2025 - AI coding agent drops production database
- Fortune: Replit Catastrophic Failure, July 2025 - Replit CEO response to database destruction incident
- The Register: Devin Poor Reviews, January 2025 - Coverage of autonomous coding agent dead-end loops
- Answer.AI: Can AI Do My Job? Devin Evaluation, January 2025 - Primary research on Devin's impossible-solution pursuit patterns